Внутренние интерфейсы персонального компьютера. Организация процесса автоматизированного проектирования
WiFi модули и другие подобные устройства. Разработку данной шины начала компания Intel в 2002 году. Сейчас разработку новых версий данной шины занимается некоммерческая организация PCI Special Interest Group.
На данный момент шина PCI Express полностью заменила такие устаревшие шины как AGP, PCI и PCI-X. Шина PCI Express размещается в нижней части материнской платы в горизонтальном положении.
В чем отличия PCI Express от PCI
PCI Express это шина, которая была разработана на основе шины PCI. Основные отличия между PCI Express и PCI лежат на физическом уровне. В то время как PCI использует общую шину, в PCI Express используется топология типа звезда. Каждое устройство подключается к общему коммутатору отдельным соединением.
Программная модель PCI Express во многом повторяет модель PCI. Поэтому большинство существующих PCI контроллеров могут быть легко доработаны для использования шины PCI Express.
Слоты PCI Express и PCI на материнской плате
Кроме этого, шина PCI Express поддерживает такие новые возможности как:
- Горячее подключение устройств;
- Гарантированная скорость обмена данными;
- Управление потреблением энергии;
- Контроль целостности передаваемой информации;
Как работает шина PCI Express
Для подключения устройств шина PCI Express использует двунаправленное последовательное соединение. При этом такое соединение может иметь одну (x1) или несколько (x2, x4, x8, x12, x16 и x32) отдельных линий. Чем больше таких линий используется, тем большую скорость передачи данных может обеспечить шина PCI Express. В зависимости от количества поддерживаемых линий размер сорта на материнской плате будет отличаться. Существуют слоты с одной (x1), четырьмя (x4) и шестнадцатью (x16) линиями.

Наглядная демонстрация размеров слота PCI Express
При этом любое PCI Express устройство может работать в любом слоте, если слот имеет такое же или большее количество линий. Это позволяет установить PCI Express карту с разъемом x1 в слот x16 на материнской плате.
Пропускная способность PCI Express зависит от количества линий и версии шины.
|
В одну/обе стороны в Гбит/с |
|||||||
|
Количество линий |
|||||||
| PCIe 1.0 | 2/4 | 4/8 | 8/16 | 16/32 | 24/48 | 32/64 | 64/128 |
| PCIe 2.0 | 4/8 | 8/16 | 16/32 | 32/64 | 48/96 | 64/128 | 128/256 |
| PCIe 3.0 | 8/16 | 16/32 | 32/64 | 64/128 | 96/192 | 128/256 | 256/512 |
| PCIe 4.0 | 16/32 | 32/64 | 64/128 | 128/256 | 192/384 | 256/512 | 512/1024 |
Примеры PCI Express устройств
В первую очередь PCI Express используется для подключения дискретных видеокарт. С момента появления данной шины абсолютно все видеокарты используют именно ее.

Видеокарта GIGABYTE GeForce GTX 770
Однако это далеко не все что умеет шина PCI Express. Ее используют производители других комплектующих.

Звуковая карта SUS Xonar DX

SSD накопитель OCZ Z-Drive R4 Enterprise
Шина ISA
Стандарты шинного интерфейса
По мере увеличения разрядности шины и увеличения тактовой частоты в компьютере, изменялись и стандарты шинного интерфейса. В настоящее время в компьютерах используются следующие основные стандарты шинного интерфейса:
· шина ISA;
· шина PCI;
Другие стандарты, такие как МСА (Micro Channel Architecture – микроканальная архитектура), EISA (Extended Industry Standard Architecture – расширенная стандартная промышленная архитектура) и VESA, обычно называемый локальной шиной, VL-шиной и разработанный ассоциацией VESA (Video Electronics Standards Association – ассоциация стандартов видеоэлектроники), в настоящее время не используются.
Первый распространенный стандарт шинного интерфейса – шина ISA (Industry Standard Architecture – стандартная промышленная архитектура) была разработана фирмой IBM при создании компьютера IBM PC AT (1984 г.). Эта 16-битовая шина с тактовой частотой 8,33 МГц допускает установку как 8-битовых, так и 16-битовых плат расширения (с пропускной способностью соответственно 8,33 и 16,6 Мбайт/с).
Обмен данными между высокоскоростными внешними устройствами и оперативной памятью выполняется при участии процессора, что в некоторых случаях может привести к снижению производительности компьютера. В режиме прямого доступа, введенном в шине ISA, периферийное устройство связано с оперативной памятью напрямую через каналы DMA (Direct Memory Access – прямой доступ в память). Наиболее эффективным такой режим обмена данными бывает в ситуациях, когда требуется высокая скорость для передачи большого объема информации (например, при загрузке данных в память с жесткого диска).
Для организации прямого доступа в память используется контроллер DMA, встроенный в одну из микросхем на материнской плате. Устройство, требующее прямой доступ к памяти, по одному из свободных каналов DMA обращается к контроллеру, сообщая ему путь (адрес), откуда или куда переслать данные, начальный адрес блока данных и объем данных. Инициализация обмена происходит с участием процессора, но собственно передача данных осуществляется уже под управлением контроллера DMA, а не процессора.
Шина ISA отсутствует в современных материнских платах, и сохранилась только в старых компьютерах.
Шина PCI (Peripheral Component Interconnect – взаимосвязь периферийных компонент) была разработана фирмой Intel с участием ряда других фирм в 1993 г. для своего нового высокопроизводительного процессора Pentium.
В настоящее время все стандарты PCI разрабатываются и поддерживаются организацией PCI-SIG (PCI – Special Interest Group) (PCI – Группа специальных интересов).
Последний стандарт PCI – PCI 3.0, принятый в 2004 году, определяет как 32-разрядную шину с тактовой частотой 33 МГц и пиковой пропускной способностью 133 Мбайта/с, так и 64-разрядные шины с тактовыми частотами 33 и 66 МГц и пиковыми пропускными способностями соответственно 266 и 533 Мбайта/с.
Для ускорения передачи данных в шине PCI используется пакетный режим (burst mode). В этом режиме данные, расположенные по какому-либо адресу, передаются не по одному, а сразу целым набором.
Основополагающим принципом, положенным в основу шины PCI, является применение так называемых мостов (bridges), которые осуществляют связь между шиной PCI и другими шинами. Важной особенностью шины PCI является и то, что в ней вместо каналов DMA реализован более эффективный режим управления шиной (Bus Mastering), который позволяет внешнему устройству управлять шиной без участия процессора. Во время передачи информации устройство, поддерживающее Bus Mastering, захватывает шину и становится главным. При таком подходе центральный процессор освобождается для выполнения других задач, пока происходит передача данных. Это особенно важно при использовании многозадачных операционных систем типа Windows и Unix.
Разъемы для карты PCI на материнской плате приведен на рис. ?????.
Рис. ?????. Разъемы для карты PCI на материнской плате:
а) 32-разрядный разъем; б) 64-разрядный разъем
Дополнением к стандарту PCI является стандарт PCI Hot Plug v1.0. Устройства PCI, удовлетворяющие этому стандарту, можно вставлять в разъем или вынимать из разъема во время работы компьютера – так называемое «горячее» подключение (hot plug).
Шины стандарта PCI используются в современных компьютерах для подключения внутренних устройств системного блока, таких как звуковая карта или модем. Однако для графических устройств эти шины имеют недостаточную скорость передачи данных, поэтому PCI-SIG был разработан новый стандарт – PCI-X (символ X означает eXtended – расширенный) с тактовыми частотами 66, 133, 266 и 533 МГц и пиковыми пропускными способностями соответственно 533, 1066, 2132 и 4264 Мбайт/с. Этот стандарт обратно совместим со стандартом PCI 3.0, т.е. в компьютере можно использовать и карты PCI 3.0 и карты PCI-X.
Последняя версия стандарта PCI-X – PCI-X 2.0 была принята в 2002 году. В настоящее время шины этого стандарта практически не используются, поскольку в этом же году PCI-SIG начала разработку принципиально нового стандарта шины PCI – PCI Express.
Стандарт PCI Express, называемый также PCI-E или PCe, предполагает замену параллельной разделяемой структуры, используемой шиной PCI и PCI-X, последовательным соединением устройств с использованием коммутаторов (switches). Старое название этого стандарта – 3GIO (3 rd Generation Input/Output – третье поколение ввода/вывода).
Последним действующим стандартом PCI Express является стандарт PCI Express Base 2.0, принятый в 2006 году.
В отличие от стандарта PCI, в котором все устройства подключаются к общей 32-разрядной параллельной однонаправленной шине, в PCI Express для подключения устройства используется одно или несколько двунаправленных последовательных соединений типа точка-точка, реализованных на медной витой паре.
При обмене данными по витой паре используется метод низковольтной дифференциальной передачи сигналов – LVDS (Low-Voltage Differential Signaling). Данные в LVDS передаются последовательно, бит за битом. При этом для передачи одного сигнала используется дифференциальная пара, т.е. что передающая сторона подаёт на проводники пары различные уровни напряжения, которые сравниваются на приёмной стороне. Для кодирования информации используется разница напряжений на проводниках пары. Небольшая амплитуда сигнала, а также незначительное электромагнитное влияние проводов пары друг на друга позволяют уменьшить шумы в линии и передавать данные на высоких частотах, т.е. с большой скоростью. Для повышения скорости передачи данных можно использовать несколько соединений (витых пар), по которым биты передаются параллельно, т.е. одновременно.
В PCI Express для передачи данных могут использоваться одно или несколько соединений. Количество соединений для устройства задается с помощью числа, за которым (или перед которым) указывается буква x. В настоящее время в спецификации определены соединения 1x, 2x, 4x, 8x, 16x и 32x. Для каждого из этих соединений шины PCI Express (за исключением соединения 32x, который пока не используется) определен свой вид разъема. На рис. ???? приведены наиболее распространенные разъемы PCI Express: 1x, 2x, 4x, 8x и 16x.

Рис. ?????. Наиболее распространенные разъемы PCI Express: а) слот 1x; б) слот 4x;
в) слот 8x; г) слот 16x;
Пропускная способность в шине PCI Express по одному соединению в настоящее время составляет 2,5 Гбит/с с перспективой увеличения до 10 Гбит/с. Стандарт PCI Express должен заменить стандарты PCI и PCI-X, а также рассматриваемый в следующем разделе стандарт AGP. Однако стандарт PCI Express совместим с этими стандартами и, видимо долго будет использоваться с ними совместно, поскольку в настоящее время выпущено и продолжает выпускаться много карт по стандартам PCI и AGP.
Доминирующее положение на рынке ПК достаточное длительное время занимали системы на основе шины PCI (Peripheral Component Interconnect – Взаимодействие периферийных компонентов). Этот интерфейс был предложен фирмой Intel в 1992 году (стандарт PCI 2.0 – в 1993) в качестве альтернативы локальной шине VLB/VLB2. Следует отметить, что разработчики этого интерфейса позиционируют PCI не как локальную, а как промежуточную шину (mezzanine bus), т.к. она не является шиной процессора. Поскольку шина PCI не ориентирована на определенный процессор, ее можно использовать для других процессоров. Шина PCI была адаптирована к таким процессорам, как Alpha, MIPS, PowerPC и SPARC. Именно PCI сменила NuBus на платформе Apple Macintosh.
Шины ISA, EISA или MCA могут управляться шиной PCI с помощью моста сопряжения (рис. 41), что позволяет устанавливать в ПК платы устройств ввода-вывода с различными системными интерфейсами. Например, в чипсете Intel Triton использовалась микросхема PIIX, помимо контроллера IDE предоставляющая мост для шины ISA.
Рис. 41. Система на основе PCI.
Существуют три варианта плат PCI: с уровнями сигналов 3,3 В, с уровнями сигналов 5 В и универсальные. Ключ в разъеме гарантирует, что платы с одним уровнем сигнала и невзаимозаменяемые не будут по ошибке вставлены в разъем с другим уровнем сигнала. Платы с пониженным напряжением питания в основном используются в мобильных компьютерах.
Существует 32-разрядная и 64-разрядная реализация шины PCI. В 64-разрядной реализации используется разъем с дополнительной секцией. 32-разрядные и 64-разрядные платы можно устанавливать в 64-разрядные и 32-разрядные разъемы и наоборот. Платы и шина определяют тип разъема и работают должным образом. При установке 64-разрядной платы в 32-разрядный разъем остальные выводы не задействуются и просто выступают за пределы разъема.
На шине PCI сигналы адреса и данных мультиплексированы, поэтому для передачи каждых 32 или 64 разрядов требуется два шинных цикла: один - для пересылки адреса, а второй - для пересылки данных. Однако возможен также пакетный режим, при котором вслед за одним циклом передачи адреса разрешается осуществить до четырех циклов передачи данных (до 16 байт в PCI-32). После этого устройство должно подать новый запрос на обслуживание и снова получить управление над шиной (и выполнить адресный цикл). Поэтому шина PCI-32 с тактовой частотой 33 МГц имеет пиковую скорость обычной передачи около 66 Мбайт/с (два шинных цикла для передачи 4 байт) и пиковую скорость пакетной передачи около 105 Мбайт/с.
PCI поддерживает процедуру прямого доступа к памяти ведущего устройства на шине (bus mastering DMA), хотя некоторые реализации PCI могут и не предоставлять такую возможность для всех разъемов PCI. Процессор может функционировать параллельно с периферийными устройствами, являющимися ведущими на шине.
Кроме того, платы PCI поддерживают:
· автоматическую конфигурацию Plug&Play (не требуют назначения адресов расширений BIOS вручную);
· совместное использование прерываний (когда один и тот же номер прерывания может использоваться разными устройствами);
· контроль четности сигналов шины данных и адресной шины;
· конфигурационную память от 64 до 256 байт (код производителя, код устройства, код класса (функции) устройства и др.).
Персональные компьютеры могут иметь две или больше шин PCI. Каждой шиной управляет свой мост PCI, что позволяет устанавливать в компьютер больше плат PCI (вплоть до 16 – ограничение адресации). Если управление второй шиной PCI осуществляется с первой шины, то это называется каскадной или иерархической схемой. В этом случае первая шина будет также нести нагрузку второй шины. Если управление каждой шиной PCI осуществляется непосредственно с шины процессора, это называется равноправной схемой. Обычно мост PCI выполняет также функции контроллера внешней кэш-памяти, контроллера основной памяти и обеспечивает сопряжение с процессором. В системах на основе Pentium II/III эти функции распределены между двумя мостами: "северным" (North Bridge) и "южным" (South Bridge), что связано с наличием дополнительного высокоскоростного системного интерфейса для подключения видеокарты (AGP).
В 1995 году был выпущена улучшенная версия интерфейса – PCI 2.1, которая предоставила следующие возможности:
· поддержка тактовой частоты шины 66 МГц;
· таймер обработки множественных запросов MTT (Multi-Transaction Timer) позволяет устройствам, осуществляющим прямой доступ к памяти, удерживать шину для "прерывистой" передачи пакетов, при этом не требуется повторно добиваться права управления шиной, что особенно полезно при передаче видеоданных;
· пассивное разъединение (Passive Release) позволяет устройствам, осуществляющим прямой доступ к памяти по шине PCI, передавать данные в то время, когда ведется передача данных по шине ISA (обычно это приводило к блокированию передачи по шине PCI, поскольку она использовалась для подключения центрального процессора к шине ISA);
· задержанные транзакции PCI позволяют передаваемым данным ведущего устройства на шине PCI получать приоритет над ожидающими в очереди данными для передачи с PCI на ISA (которые будут переданы позже);
· повышение производительности записи благодаря оснащению PCI-чипсета буферами большего объема, поэтому транзакции могут выстраиваться в очередь, когда шина PCI занята, и происходит сбор байтов, слов и двойных слов, которые могут объединяться в единую 8-байтную операцию записи.
C 2005 года в ПК на основе Pentium 4 вместо PCI используют новый системный интерфейс – PCI Express.
Конец работы -
Эта тема принадлежит разделу:
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
Сибирский государственный аэрокосмический университет... имени академика М Ф Решетнева... ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Все темы данного раздела:
Уровни детализации структуры вычислительной машины
Вычислительная машина как законченный объект являет собой плод усилий специалистов в самых различных областях человеческих знаний. Каждый специалист рассматривает вычислительную ма
Эволюция средств автоматизации вычислений
Попытки облегчить, а в идеале автоматизировать процесс вычислений имеют давнюю историю, насчитывающую более 5000 лет. С развитием науки и технологий средства автоматизации вычислений непрерывно сов
Нулевое поколение (1492-1945)
Для полноты картины упомянем два события, произошедшие до нашей эры: первые счеты - абак, изобретенные в древнем Вавилоне за 3000 лет до н. э., и их более «современный» вариант с к
Первое поколение(1937-1953)
На роль первой в истории электронной вычислительной машины в разные периоды претендовало несколько разработок. Общим у них было использование схем на базе электронно-вакуумных ламп
Второе поколение (1954-1962)
Второе поколение характеризуется рядом достижений в элементной базе, структуре и программном обеспечении. Принято считать, что поводом для выделения нового поколения ВМ стали техно
Третье поколение (1963-1972)
Третье поколение ознаменовалось резким увеличением вычислительной мощности ВМ, ставшим следствием больших успехов в области архитектуры, технологии и программного обеспечения. Осно
Четвертое поколение (1972-1984)
Отсчет четвертого поколения обычно ведут с перехода на интегральные микросхемы большой (large-scale integration, LSI) и сверхбольшой (very large-scale integration, VLSI) степени и
Пятое поколение (1984-1990)
Главным поводом для выделения вычислительных систем второй половины 80-х годов в самостоятельное поколение стало стремительное развитие ВС с сотнями процессоров, ставшее побудитель
Концепция машины с хранимой в памяти программой
Исходя из целей данного раздела, введем новое определение термина «вычислительная машина» как совокупности технических средств, служащих для автоматизированной обработки дискретны
Принцип двоичного кодирования
Согласно этому принципу, вся информация, как данные, так и команды, кодируются двоичными цифрами 0 и 1. Каждый тип информации представляется двоичной последовательностью и имеет св
Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей из последовательности управляющих слов - команд. Каждая команда пред
Принцип однородности памяти
Команды и данные хранятся в одной и той же памяти и внешне в памяти неразличимы. Распознать их можно только по способу использования. Это позволяет производить над командами те же
Фон-неймановская архитектура
В статье фон Неймана определены основные устройства ВМ, с помощью которых должны быть реализованы вышеперечисленные принципы. Большинство современных ВМ по своей структуре отвечают принципу програ
Структуры вычислительных машин
В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе шины.
Типичным представи
Структуры вычислительных систем
Понятие «вычислительная система» предполагает наличие множества процессоров или законченных вычислительных машин, при объединении которых используется один из двух подходов.
Перспективные направления исследований в области архитектуры
Основные направления исследований в области архитектуры ВМ и ВС можно условно разделить на две группы: эволюционные и революционные. К первой группе следует отнести исследования,
Понятие архитектуры системы команд
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь, под архитектурой системы команд (АСК) принято определят
Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, ко
Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр - аккуму
Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН). Эти регистры, в каком-то смысле, можно рассматр
Архитектура с выделенным доступом к памяти
В архитектуре с выделенным доступом к памяти обращение к основной памяти возможно только с помощью двух специальных команд: load и store. В английской транскрипции данную архитектуру
Форматы команд
Типовая команда, в общем случае, должна указывать:
· подлежащую выполнению операцию;
· адреса исходных данных (операндов), над которыми выполняется операция;
· адрес, по
Длина команды
Это важнейшее обстоятельство, влияющее на организацию и емкость памяти, структуру шин, сложность и быстродействие ЦП. С одной стороны, удобно иметь в распоряжении мощный набор команд, то есть как м
Разрядность адресной части
В адресной части команды содержится информация о местонахождении исходных данных и месте сохранения результата операции. Обычно местонахождение каждого из операндов и результата задается в команде
Количество адресов в команде
Для определения количества адресов, включаемых в адресную часть, будем использовать термин адресность. В «максимальном» варианте необходимо указать три компонента: адрес первого опе
Адресность и время выполнения программы
Время выполнения одной команды складывается из времени выполнения операции и времени обращения к памяти.
Для трехадресной команды последнее суммируется из четырех составля
Способы адресации операндов
Вопрос о том, каким образом в адресном поле команды может быть указано местоположение операндов, считается одним из центральных при разработке архитектуры ВМ. С точки зрения сокра
Непосредственная адресация
При непосредственной адресации (НА) в адресном поле команды вместо адреса содержится непосредственно сам операнд (рис. 15). Этот способ может применяться при выполнении арифметичес
Прямая адресация
При прямой или абсолютной адресации (ПА) адресный код прямо указывает номер ячейки памяти, к которой производится обращение (рис. 22), то есть адресный код совпадает с исполнительн
Косвенная адресация
Одним из путей преодоления проблем, свойственных прямой адресации, может служить прием, когда с помощью ограниченного адресного поля команды указывается адрес ячейки, в свою очеред
Регистровая адресация
Регистровая адресация (РА) напоминает прямую адресацию. Различие состоит в том, что адресное поле инструкции указывает не на ячейку памяти, а на регистр процессора (рис. 24). Иденти
Косвенная регистровая адресация
Косвенная регистровая адресация (КРА) представляет собой косвенную адресацию, где исполнительный адрес операнда хранится не в ячейке основной памяти, а в регистре процессора. Соотв
Адресация со смещением
При адресации со смещением исполнительный адрес формируется в результате суммирования содержимого адресного поля команды с содержимым одного или нескольких регистров процессора (рис
Относительная адресация
При относительной адресации (ОА) для получения исполнительного адреса операнда содержимое подполя Aк команды складывается с содержимым счетчика команд (рис. 27). Таким
Базовая регистровая адресация
В случае базовой регистровой адресации (БРА) регистр, называемый базовым, содержит полноразрядный адрес, а подполе Ас - смещение относительно этого адреса. Ссылка на ба
Индексная адресация
При индексной адресации (ИА) подполе Ас содержит адрес ячейки памяти, а регистр (указанный явно или неявно) - смещение относительно этого адреса. Как видно, этот способ
Страничная адресация
Страничная адресация (СТА) предполагает разбиение адресного пространства на страницы. Страница определяется своим начальным адресом, выступающим в качестве базы. Старшая часть этог
Цикл команды
Программа в фон-неймановской ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд. Действия, требуемые для выборки (
Основные показатели вычислительных машин
Использование конкретной вычислительной машины имеет смысл, если ее показатели соответствуют показателям, определяемым требованиями к реализации заданных алгоритмов. В качестве осно
Программная архитектура i80х86
Одним из наиболее распространенных процессоров общего назначения на данный момент являются процессоры с архитектурой x86 (Intel IA-32). Родоначальником семейства этих процессоров явился ЦП i8086. И
Сегмент кода.
В сегменте кода обычно записываются команды микропроцессора, которые выполняются последовательно друг за другом. Для определения адреса следующей команды после выполнения предыдущей
Переменные в программе.
Во всех остальных сегментах выделяется место для переменных, используемых в программе. Разделение на сегменты данных, сегмент стека и сегмент дополнительных данных связано с тем, чт
Сегмент стека.
Для хранения временных значений, для которых нецелесообразно выделять переменные, предназначена специальная область памяти, называемая стеком. Для адресации такой области служит сег
Микропроцессор i8086
С точки зрения программиста микропроцессор представляется в виде набора регистров. Регистры предназначены для хранения некоторых данных и поэтому, в некотором смысле, они соответств
Доступ к ячейкам памяти
Как уже отмечалось, в состав любой микропроцессорной системы обязательно должна входить память, в которой располагаются программы и необходимые для их работы данные. Физическая и ло
Команды микропроцессора
Программа, работающая в микропроцессорной системе, в конечном виде представляет собой набор байтов, воспринимаемый микропроцессором как код той или иной команды вместе с соответству
Основные группы команд и их краткая характеристика
Для упрощения процесса программирования на языке ассемблера используется мнемоническая запись команд микропроцессора (обычно в виде сокращений английских слов, описывающих действия
Способы адресации в архитектуре i80x86
Рассмотренные выше способы адресации могут быть в полной мере применены при написании программы на языке ассемблера. Рассмотрим методы реализации наиболее часто применяющихся способ
Адресация ячеек памяти
Кроме регистров и констант в командах можно использовать ячейки памяти. Естественно, что они могут использоваться и как источник и как приемник данных.
Более точно, в командах используется
Прямая адресация
При прямой адресации в команде указывается смещение, которое соответствует началу размещения в памяти соответствующего операнда. По умолчанию, при использовании упрощенных директив описания сегмент
Косвенная адресация
При косвенной адресации смещение соответствующего операнда в сегменте содержится в одном из регистров микропроцессора. Таким образом, текущее содержимое регистра микропроцессора определяет исполнит
Косвенная адресация по базе
При использовании косвенной адресации к содержимому регистра можно добавлять константу. В этом случае исполнительный адрес вычисляется как сумма содержимого соответствующего регистра и этой констан
Адресация по базе с индексированием
В микропроцессоре i8086 можно использовать также комбинацию косвенной индексной адресации и адресации по базе. Исполнительный адрес операнда определяется как сумма трех составляющих – содержимого д
Лабораторная работа №1. Программная архитектура процессора i8086
На языке ассемблера процессора i8086 с использованием любого удобного пакета (рекомендуется TASM) реализуйте следующие задачи:
1. Протабулировать функцию у
Структура взаимосвязей вычислительной машины
Совокупность трактов, объединяющих между собой основные устройства ВМ (центральный процессор, память и модули ввода/вывода), образует структуру взаимосвязей вычислительной машины.
Типы шин
Важным критерием, определяющим характеристики шины, может служить ее целевое назначение. По этому критерию можно выделить:
· шины «процессор-память»;
· шины ввода
Системная шина
С целью снижения стоимости некоторые ВМ имеют общую шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Системная шина служит для физического и логическ
Вычислительная машина с одной шиной
В структурах взаимосвязей с одной шиной имеется одна системная шина, обеспечивающая обмен информацией между процессором и памятью, а также между УВВ с одной стороны, и процессором л
Вычислительная машина с двумя видами шин
Хотя контроллеры устройств ввода/вывода (УВВ) могут быть подсоединены непосредственно к системной шине, больший эффект достигается применением одной или нескольких шин ввода/вывод
Вычислительная машина с тремя видами шин
Для подключения быстродействующих периферийных устройств в систему шин может быть добавлена высокоскоростная шина расширения.
Механические аспекты
Основная шина, объединяющая устройства вычислительной машины, обычно размещается на так называемой объединительной или материнской плате. Шину образуют тонкие параллельные медные по
Электрические аспекты
Все устройства, использующие шину, электрически подсоединены к ее сигнальным линиям, представляющим собой электрические проводники. Меняя уровни напряжения на сигнальных линиях, ве
Распределение линий шины
Любая транзакция на шине начинается с выставления ведущим устройством адресной информации. Адрес позволяет выбрать ведомое устройство и установить соединение между ним и ведущим. Д
Выделенные и мультиплексируемые линии
В некоторых ВМ линии адреса и данных объединены в единую мультиплексируемую шину адреса/данных. Такая шина функционирует в режиме разделения времени, поскольку цикл шины разбит на
Схемы приоритетов
Каждому потенциальному ведущему присваивается определенный уровень приоритета, который может оставаться неизменным (статический или фиксированный приоритет) либо изменяться по како
Схемы арбитража
Арбитраж запросов на управление шиной может быть организован по централизованной или децентрализованной схеме. Выбор конкретной схемы зависит от требований к производительности и
Порт AGP
С повсеместным внедрением технологий мультимедиа пропускной способности шины PCI стало не хватать для производительной работы видеокарты. Чтобы не менять сложившийся стандарт на шин
PCI Express
Интерфейс PCI Express (первоначальное название - 3GIO) использует концепцию PCI, однако физическая их реализация кардинально отличается. На физическом уровне PCI Express представляе
Локализация данных
Под локализацией данных будем понимать возможность обращения к одному из ВУ, а также адресации данных на нем.
Адрес ВУ обычно содержится в адресной части команд ввода/вывод
Управление и синхронизация
Функция управления и синхронизации заключается в том, что МВВ должен координировать перемещение данных между внутренними ресурсами ВМ и внешними устройствами. При разработке систем
Обмен информацией
Основной функцией МВВ является обеспечение обмена информацией. Со стороны «большого» интерфейса - это обмен с ЦП, а со стороны «малого» интерфейса - обмен с ВУ. В таком плане треб
Система прерываний и исключений в архитектуре IA-32
Прерывания и исключения - это события, которые указывают на возникновение в системе или в выполняемой в данный момент задаче определенных условий, требующих вмешательства процессора
Расширенный программируемый контроллер прерываний (APIC)
Микропроцессоры IA-32, начиная с модели Pentium, содержат встроенный расширенный программируемый контроллер прерываний (APIC). Встроенный APIC предназначен для регистрирования преры
Конвейеризация вычислений
Совершенствование элементной базы уже не приводит к кардинальному росту производительности ВМ. Более перспективными в этом плане представляются архитектурные приемы, среди которых о
Синхронные линейные конвейеры
Эффективность синхронного конвейера во многом зависит от правильного выбора длительности тактового периода Тк. Минимально допустимую Тк можно определить как
Метрики эффективности конвейеров
Чтобы охарактеризовать эффект, достигаемый за счет конвейеризации вычислений, обычно используют три метрики: ускорение, эффективность и производительность.
Под ускорен
Нелинейные конвейеры
Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соотв
Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком С. А. Лебедевым. Как известно, цикл команды представляет собой последовательность этапов. Возложив реализацию каждого из
Конфликты в конвейере команд
Полученное в примере число 14 характеризует лишь потенциальную производительность конвейера команд, На практике в силу возникающих в конвейере конфликтных ситуаций достичь такой про
Методы решения проблемы условного перехода
Несмотря на важность аспекта вычисления исполнительного адреса точки перехода, основные усилия проектировщиков ВМ направлены на решение проблемы условных переходов, поскольку именн
Предсказание переходов
Предсказание переходов на сегодняшний день рассматривается как один из наиболее эффективных способов борьбы с конфликтами по управлению. Идея заключается в том, что еще до момента
Статическое предсказание переходов
Статическое предсказание переходов осуществляется на основе некоторой априорной информации о подлежащей выполнению программе. Предсказание делается на этапе компиляции программы и
Динамическое предсказание переходов
В динамических стратегиях решение о наиболее вероятном исходе команды УП принимается в ходе вычислений, исходя из информации о предшествующих переходах (истории переходов), собирае
Суперконвейерные процессоры
Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно
Архитектуры с полным и сокращенным набором команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная задача которых - облегчить процесс написания программ. Более 90% всего процесса програм
Основные черты RISC-архитектуры
Главные усилия в архитектуре RISC направлены на построение максимально эффективного конвейера команд, то есть такого, где все команды извлекаются из памяти и поступают в ЦП на обр
Преимущества и недостатки RISC
Сравнивая достоинства и недостатки CISC и RISC, невозможно сделать однозначный вывод о неоспоримом преимуществе одной архитектуры над другой. Для отдельных сфер использования ВМ л
Суперскалярные процессоры
Поскольку возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности ВМ лежит в плоскости архитектурных решений. Как уже о
Лабораторная работа №4. Исполнительные устройства ВМ
Счетчики.Счетчиком называют устройство, сигналы на выходе которого отображают число импульсов, поступивших на счетный вход. JK-триггер может служить примером просте
Характеристики систем памяти
Перечень основных характеристик, которые необходимо учитывать, рассматривая конкретный вид ЗУ, включает в себя:
· место расположения;
· емкость;
· единицу
Иерархия запоминающих устройств
Память часто называют «узким местом» фон-неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем разрыв этот неуклонно увеличивается. Так, если прои
Основная память
Основная память (ОП) представляет собой единственный вид памяти, к которой ЦП может обращаться непосредственно (исключение составляют лишь регистры центрального процессора). Информация, хранящая
Блочная организация основной памяти
Емкость основной памяти современных ВМ слишком велика, чтобы ее можно было реализовать на базе единственной интегральной микросхемы (ИМС). Необходимость объединения нескольких ИМС
Организация микросхем памяти
Интегральные микросхемы (ИМС) памяти организованы в виде матрицы ячеек, каждая из которых, в зависимости от разрядности ИМС, состоит из одного или более запоминающих элементов (ЗЭ)
Синхронные и асинхронные запоминающие устройства
В качестве первого критерия, по которому можно классифицировать запоминающие устройства основной памяти, рассмотрим способ синхронизации. С этих позиций известные типы ЗУ подразде
Оперативные запоминающие устройства
Большинство из применяемых в настоящее время типов микросхем оперативной памяти не в состоянии сохранять данные без внешнего источника энергии, то есть являются энергозависимыми (vo
Статическая и динамическая оперативная память
В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий элемент динамического
Статические оперативные запоминающие устройства
Напомним, что роль запоминающего элемента в статическом ОЗУ исполняет триггер. Статические ОЗУ на настоящий момент – наиболее быстрый, правда, и наиболее дорогостоящий вид оперативн
Динамические оперативные запоминающие устройства
Динамической памяти в вычислительной машине значительно больше, чем статической, поскольку именно DRAM используется в качестве основной памяти ВМ. Как и SRAM, динамическая память с
Лабораторная работа №5. Расширенная работа с памятью и передача управления в программе
Реализуйте на языке ассемблера микропроцессора i8086 следующие программы, используя команды передачи управления call и ret:
1. Определить резу
Магнитные диски
Информация в ЗУ на магнитных дисках (МД) хранится на плоских металлических или пластиковых пластинах (дисках), покрытых магнитным материалом. Данные записываются и считываются с д
Организация данных и форматирование
Данные на диске организованы в виде набора концентрических окружностей, называемых дорожками (рис. 72). Каждая из них имеет ту же ширину, что и головка. Соседние дорожки разделены промежутками. Эт
Внутреннее устройство дисковых систем
В ЗУ с фиксированными головками приходится по одной головке считывания/ записи на каждую дорожку. Головки смонтированы на жестком рычаге, пересекающем все дорожки диска. В дисковом
Концепция массива с избыточностью
Магнитные диски, будучи основой внешней памяти любой ВМ, одновременно остаются и одним из «узких мест» из-за сравнительно высокой стоимости, недостаточной производительности и отк
Повышение производительности дисковой подсистемы
Повышение производительности дисковой подсистемы в RAID достигается с помощью приема, называемого расслоением или расщеплением (striping). В его основе лежит разбиение данных и ди
Повышение отказоустойчивости дисковой подсистемы
Одной из целей концепции RAID была возможность обнаружения и коррекции ошибок, возникающих при отказах дисков или в результате сбоев. Достигается это за счет избыточного дискового п
RAID уровня 0
RAID уровня 0, строго говоря, не является полноценным членом семейства RAID, поскольку данная схема не содержит избыточности и нацелена только на повышение производительности в уще
RAID уровня 1
В RAID 1 избыточность достигается с помощью дублирования данных. В принципе исходные данные и их копии могут размещаться по дисковому массиву произвольно, главное чтобы они находи
RAID уровня 2
В системах RAID 2 используется техника параллельного доступа, где в выполнении каждого запроса на В/ВЫВ одновременно участвуют все диски. Обычно шпиндели всех дисков синхронизиров
RAID уровня 3
RAID 3 организован сходно с RAID2. Отличие в том, что RAID 3 требует только одного дополнительного диска - диска паритета, вне зависимости от того, насколько велик массив дисков (р
RAID уровня 4
По своей идее и технике формирования избыточной информации RAID 4 идентичен RAID 3, только размер полос в RAID 4 значительно больше (обычно один-два физических блока на диске). Гла
RAID уровня 5
RAID 5 имеет структуру, напоминающую RAID 4. Различие заключается в том, что RAID 5 не содержит отдельного диска для хранения полос паритета, а разносит их по всем дискам. Типичное
RAID уровня 6
RAID 6 очень похож на RAID 5. Данные также разбиваются на полосы размером в блок и распределяются по всем дискам массива. Аналогично, полосы паритета распределены по разным дискам.
RAID уровня 7
Схема RAID 7, запатентованная Storage Computer Corporation, объединяет массив асинхронно работающих дисков и кэш-память, управляемые встроенной в кон троллер массива операционной с
RAID уровня 10
Данная схема совпадает с RAID 0, но в отличие от нее роль отдельных дисков выполняют дисковые массивы, построенные по схеме RAID 1 (рис. 83).
Таким образом, в RAID 10 соче
Особенности реализации RAID-систем
Массивы RAID могут быть реализованы программно, аппаратно или как комбинация программных и аппаратных средств.
При программной реализации используются обычные дисковые кон
Оптическая память
В 1983 году была представлена первая цифровая аудиосистема на базе компакт-дисков (CD - compact disk). Компакт-диск - это односторонний диск, способный хранить более чем 60-минутную
Уровни параллелизма
Методы и средства реализации параллелизма зависят от того, на каком уровне он должен обеспечиваться. Обычно различают следующие уровни параллелизма:
· Уровень заданий. Неск
Параллелизм уровня программ
О параллелизме на уровне программы имеет смысл говорить в двух случаях. Во-первых, когда в программе могут быть выделены независимые участки, которые допустимо выполнять параллельно
Параллелизм уровня команд
Параллелизм на уровне команд имеет место, когда обработка нескольких команд или выполнение различных этапов одной и той же команды может перекрываться во времени. Разработчики вычис
Профиль параллелизма программы
Число процессоров многопроцессорной системы, параллельно участвующих в выполнении программы в каждый момент времени t, определяют понятием степень параллелизма D(t) (
Рассмотрим параллельное выполнение программы со следующими характеристиками:
· О(п) - общее число операций (команд), выполненных на п-процессорной системе;
Закон Амдала
Приобретая для решения своей задачи параллельную вычислительную систему, пользователь рассчитывает на значительное повышение скорости вычислений за счет распределения вычислительной
Закон Густафсона
Известную долю оптимизма в оценку, даваемую законом Амдала, вносят исследования, проведенные уже упоминавшимся Джоном Густафсоном из NASA Ames Research. Решая на вычислительной сис
Когерентность кэш- памяти в SMP- системах.
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых кэшей. Тогда, если эти требования
Когерентность кэш- памяти в MPP-системах.
Существуют два различных способа построения крупномасштабных систем с распределенной памятью. Простейший способ заключается в том, чтобы исключить аппаратные механизмы, обеспечивающ
Организация прерываний в мультипроцессорных системах.
Рассмотрим реализацию прерываний в наиболее простых симметричных многопроцессорных системах, в которых используется несколько процессоров, объединенных общей шиной. Каждый процессор
ЗАКЛЮЧЕНИЕ
Охватить все аспекты строения и организации вычислительных машин в одном издании (да и в рамках одного курса) не представляется возможным. Знания в этой области человеческой деятель
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Авен, О. И. Оценка качества и оптимизации вычислительных систем / О.И. Авен, Н. Я. Турин, А. Я. Коган. – М.: Наука, 1982. – 464 с.
2. Воеводин, В. В. Параллельные вычи
В этой статье мы расскажем о причинах успеха шины PCI и дадим описание высокопроизводительной технологии, которая приходит ей на смену – шины PCI Express. Также мы рассмотрим историю развития, аппаратные и программные уровни шины PCI Express, особенности её реализации и перечислим ее преимущества.
Когда в начале 1990-x гг. она появилась, то по своим техническим характеристикам значительно превосходила все существовавшие до того момента шины, такие, как ISA, EISA, MCA и VL-bus. В то время шина PCI(Peripheral Component Interconnect - взаимодействие периферийных компонентов), работавшая на частоте 33 Мгц, хорошо подходила для большинства периферийных устройств. Но сегодня ситуация во многом изменилась. Прежде всего, значительно возросли тактовые частоты процессора и памяти. Например, тактовая частота процессоров увеличились с 33 МГц до нескольких ГГц, в то время как рабочая частота PCI увеличилась всего до 66 МГц. Появление таких технологий, как Gigabit Ethernet и IEEE 1394B грозило тем, что вся пропускная способность шины PCI может уйти на обслуживание одного-единственного устройства на основе данных технологий.
При этом архитектура PCI имеет ряд преимуществ по сравнению с предшественниками, поэтому полностью пересматривать было нерационально. Прежде всего, она не зависит от типа процессора, поддерживает буферную изоляцию, технологию bus mastering (захват шины) и технологию PnP в полном объеме. Буферная изоляция означает, что шина PCI действует независимо от внутренней шины процессора, что дает возможность шине процессора функционировать независимо от скорости и загруженности системной шины. Благодаря технологии захвата шины периферийные устройства получили возможность непосредственно управлять процессом передачи данных по шине, вместо того, чтобы ожидать помощи от центрального процессора, что отразилось бы на производительности системы. Наконец, поддержка Plug and Play позволяет осуществлять автоматическую настройку и конфигурирование пользующихся ею устройств и избежать возни с джамперами и переключателями, которая изрядно портила жизнь владельцам ISA-устройств.
Несмотря на несомненный успех PCI, в нынешнее время она сталкивается с серьезными проблемами. Среди них – ограниченная пропускная способность, недостаток функций передачи данных в реальном времени и отсутствие поддержки сетевых технологий нового поколения.
Сравнительные характеристики различных стандартов PCI
Следует учесть, что реальная пропускная способность может быть меньше теоретической из-за принципа работы протокола и особенностей топологии шины. К тому же общая пропускная способность распределяется между всеми подключенными к ней устройствами, поэтому, чем больше устройств сидит на шине, тем меньшая пропускная способность достается каждому из них.
Такие усовершенствования стандарта, как PCI-X и AGP были призваны устранить ее главный недостаток – низкую тактовую частоту. Однако увеличение тактовой частоты в этих реализациях повлекло за собой уменьшение эффективной длины шины и количества разъемов.
Новое поколение шины - PCI Express (или сокращенно PCI-E), было впервые представлено в 2004 году и было призвано решить все те проблемы, с которыми столкнулась её предшественница. Сегодня большая часть новых компьютеров снабжается шиной PCI Express. Хотя стандартные слоты PCI в них тоже присутствуют, однако не за горами то время, когда шина станет достоянием истории.
Архитектура PCI Express
Архитектура шины имеет многоуровневую структуру, как показано на рисунке.
Шина поддерживает модель адресации PCI, что позволяет работать с ней всем существующим на данный момент драйверам и приложениям. Кроме того, шина PCI Express использует стандартный механизм PnP, предусмотренный предыдущим стандартом.
Рассмотрим предназначение различных уровней организации PCI-E. На программном уровне шины формируются запросы чтения/записи, которые передаются на транспортном уровне при помощи специального пакетного протокола. Уровень данных отвечает за помехоустойчивое кодирование и обеспечивает целостность данных. Базовый аппаратный уровень состоит из двойного симплексного канала, состоящего из передающей и принимающей пары, которые вместе называются линией. Общая скорость шины в 2,5 Гб/с означает, что пропускная способность для каждой линии PCI Express составляет 250 Мб/c в каждую сторону. Если принять во внимание потери на накладные расходы протокола, то для каждого устройства доступно около 200 Мб/c. Эта пропускная способность в 2-4 раза выше, чем та, которая была доступна для устройств PCI. И, в отличие от PCI, в том случае, если пропускная способность распределяется между всеми устройствами, то она в полном объеме достается каждому устройству.
На сегодняшний день существует несколько версий стандарта PCI Express, различающихся своей пропускной способностью.
Пропускная способность шины PCI Express x16 для разных версий PCI-E, Гб/c:
- 32/64
- 64/128
- 128/256
Форматы шины PCI-E
На данный момент доступны различные варианты форматов PCI Express, в зависимости от предназначения платформы – настольный компьютер, ноутбук или сервер. Серверы, требующие большую пропускную способность, имеют больше слотов PCI-E, и эти слоты имеют большее число соединительных линий. В противоположность этому ноутбуки могут иметь лишь одну линию для среднескоростных устройств.
Видеокарта с интерфейсом PCI Express x16.
Платы расширения PCI Express очень похожи на платы PCI, однако разъемы PCI-E отличаются повышенным сцеплением, что позволяет быть уверенным в том, что плата не выскользнет из слота из-за вибрации или при транспортировке. Существует несколько форм-факторов слотов PCI Express, размер которых зависит от количества используемых линий. Например, шина, имеющая 16 линий, обозначается как PCI Express x16. Хотя общее количество линий может достигать 32, на практике большинство материнских плат в настоящее время оснащены шиной PCI Express x16.
Карты меньших форм-факторов могут подключаться в разъемы для больших без ущерба для работоспособности. Например, карта PCI Express х1 может подключаться в разъем PCI Express x16. Как и в случае шины PCI, для подключения устройств при необходимости можно использовать РCI Express-удлинитель.
Внешний вид разъемов различных типов на материнской плате. Сверху вниз: слот PCI-X, слот PCI Express х8, слот PCI, слот PCI Express х16.
Express Card
Стандарт Express Card предлагает очень простой способ добавления оборудования в систему. Целевым рынком для модулей Express Card являются ноутбуки и небольшие ПК. В отличие от традиционных плат расширения настольных компьютеров, карта Express может подключаться к системе в любой момент во время работы компьютера.
Одной из популярных разновидностей Express Card является карта PCI Express Mini Card, разработанная в качестве замены карт форм-фактора Mini PCI. Карта, созданная в этом формате, поддерживает как PCI Express, так и USB 2.0. Размеры PCI Express Mini Card составляют 30×56 мм. Карта PCI Express Mini Card может подключаться к PCI Express х1.
Преимущества PCI-E
Технология PCI Express позволила получить преимущество по сравнению с PCI в следующих пяти областях:
- Более высокая производительность. При наличии всего одной линии пропускная способность PCI Express в два раза выше, чем у PCI. При этом пропускная способность увеличивается пропорционально количеству линий в шине, максимальное количество которых может достигать 32. Дополнительным преимуществом является то, что информация по шине может передаваться одновременно в обоих направлениях.
- Упрощение ввода-вывода. PCI Express использует преимущества таких шин, как AGP и PCI-X и обладает при этом менее сложной архитектурой, а также сравнительной простотой реализации.
- Многоуровневая архитектура. PCI Express предлагает архитектуру, которая может подстраиваться к новым технологиям и не требует значительного обновления ПО.
- Технологии ввода/вывода нового поколения. PCI Express дает новые возможности получения данных при помощи технологии одновременных передач данных, обеспечивающей своевременное получение информации.
- Простота использования. PCI-E значительно упрощает обновление и расширение системы пользователем. Дополнительные форматы плат Express, такие, как ExpressCard, значительно увеличивают возможности добавления высокоскоростных периферийных устройств в серверы и ноутбуки.
Заключение
PCI Express – это технология шины для подключения периферийных устройств, пришедшая на смену таким технологиям как ISA, AGP и PCI. Её применение значительно увеличивает производительность компьютера, а также возможности пользователя по расширению и обновлению системы.
PCI (Peripheral Component Interconnent) local bus - шина соединения периферийных компонентов. Это высокопроизводительная синхронная шина, широко используемая в современных процессорных системах. В частности, для платформы РС эта шина с конца 90-х гг. являлась основной, полностью вытеснив более простую и удобную для разработчиков шину ISA. Частота синхронизации составляет 33 МГц, но допускается установка частоты 66 МГц, если ее поддерживают все периферийные устройства. Разрядность шины равна 32 или 64.
PCI обеспечивает существенно большую скорость передачи данных, чем устаревший протокол обмена ISA. Кроме повышения разрядности и тактовой частоты, к достоинствам этой шины следует отнести контроль четности при передаче данных, улучшенный протокол обмена между ведущим и ведомым устройствами и, наконец, автоматическое конфигурирование устанавливаемых плат.
Разработка собственных плат расширения, подключаемых к шине ISA, долгое время являлась удобным и дешевым способом использования ПК в системе сбора данных и управления. Низкие тактовые частоты, простая схема дешифрации и отсутствие жестких требований к разводке печатной платы позволяли выполнить контроллер ISA на базе дискретных компонентов (серии 74хх или отечественной 155 / 555). Однако спецификации PCI исключает разводку сигналов по нескольким входам микросхем на карте расширения, как того требует реализация на дискретных компонентах. Для реализации карт расширения на базе PCI выпускаются стандартные мосты (например, АМСС или PLX), однако исполнение контроллера PCI совместно с устройством пользователя в одной микросхеме выглядит довольно привлекательно. Соответственно фирма Xilinx постоянно обращала внимание на возможности подключения своих ПЛИС напрямую к этой шине, и контроллеры PCI, реализованные на базе различных устройств (преимущественно FPGA), являлись постоянной продукцией как Xilinx, так и сторонних производителей. В частности, ПЛИС Virtex-E допускали реализацию на их основе контроллеров PCI 66 МГЦ / 64 бит.
Наиболее простым вариантом исполнения является так называемый target-контроллер, работающий на частоте 33 МГц с разрядностью 32 бита. Подобные контроллеры, написанные на различных HDL, как уже упоминалось, разработаны многими фирмами, однако целью настоящего издания является продемонстрировать возможность разработки простого контроллера на VHDL для использования его в недорогих FPGA (и даже в CPLD).
Основные сигналы шины PCI, достаточные для организации простого target-контроллера, приведены в табл. 2.8 (символом # обозначены сигналы, имеющие активный низкий уровень).
Таблица 2.8
Основные сигналы шины PCI
| Значение |
|
| Сигнал тактовой частоты. Должен быть в пределах 20-33 М Гц. Допускается частота 66 МГц, если все устройства на шине явно сообщили о возможности работы в таком режиме |
|
| Мультиплексированная шина адреса / данных. В первом такте транзакции передается адрес, затем – данные |
|
| Command / Byte Enable - в первом такте передается команда, затем- биты обращения к отдельным байтам 32-разрядного числа |
|
| Сигнал «начало кадра». Введение этого сигнала указывает на начало транзакции (фаза передачи адреса и команды); снятие сигнала указывает, что следующий такт является последним в транзакции |
|
| Device Select- устройство выбрано. Устройство должно выставить этот сигнал, если распознало транзакцию, предназначенную ему (адрес попадает в адресное пространство устройства, и команда поддерживается) |
|
| Initiator Ready - системный контроллер готов к обмену данными |
|
| Target Ready - устройство готово к обмену данными |
|
| Parity - общий бит четности для линий AD и С / ВЕ# |
|
| Present - индикаторы присутствия платы в слоте PCI, сообщающие о максимальном потреблении мощности платой. По меньшей мере один из этих сигналов должен быть подключен к GND |
|
| Initialization Device Select - выбор устройства в циклах чтения и записи конфигурационного пространства |
|
| Parity Error - ошибка четности. Если карта не вырабатывает этот сигнал, он должен быть установлен в неактивное состояние |
|
| System Error - системная ошибка. Вызывает NMI. Если карта не вырабатывает этот сигнал, он должен быть установлен в неактивное состояние |
Возможные команды шины PCI приведены в табл. 2.9. Выделенные шинные циклы должны поддерживаться минимальной конфигурацией карты расширения.
Таблица 2.9
Команды шины PCI
| Сигнал C / BE# в первом такте транзакции | Тип команды |
| Interrapt Acknowledge – подтверждение прерывания |
|
| Special Cycle – специальный цикл |
|
| I / O Read - чтение порта ввода-вывода |
|
| I / O Write - запись в порт ввода-вывода |
|
| Зарезервировано |
|
| Зарезервировано |
|
| Memory Read - чтение памяти |
|
| Memory Write - запись памяти |
|
| Зарезервировано |
|
| Зарезервировано |
|
| Configuration Read - чтение конфигурационного пространства |
|
| Configuration Write – запись в конфигурационное пространство |
|
| Multiple Memory Read - множественное чтение памяти |
|
| Dual Address Cycle - двухадресный цикл |
|
| Memory Read Line - чтение строк памяти |
|
| Memory Write and Invalidate - запись в память и инвалидация |
Циклы обращения к контроллеру PCI представлены на следующих временных диаграммах (рис. 2.22 и 2.23).
Рис. 2.22. Временная диаграмма чтения устройства ввода-вывода

Рис. 2.23. Временная диаграмма записи в устройство ввода-вывода
Любая транзакция по шине начинается с установки сигнала FRAME# в активное состояние. По следующему фронту тактового сигнала на линиях AD присутствует адрес, по которому происходит обращение, а на CMD / BE# - код команды. Этой информации достаточно для того, чтобы все устройства, подключенные к шине, могли определить, предназначена ли эта транзакция для них. Если адрес попадает в адресное пространство карты и тип команды поддерживается, карта должна ответить сигналом DEVSEL#. Стандарт предусматривает задержку в установке этого сигнала для медленных устройств, однако быстродействия ПЛИС вполне хватает для своевременной реакции на частоте 33 МГц.
Последующие такты соответствуют передаче данных. В это время на линиях AD присутствуют данные, сопровождаемые сигналами разрешения отдельных байтов на C / BE#. Системный контроллер может задержать передачу снятием сигнала IRDY#, а целевое устройство - снятием сигнала TRDY#, как показано на диаграммах.
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.STD_LOGIC_ARITH.ALL;
use IEEE.STD_LOGIC_UNSIGNED.ALL;
entity pci-target is
inout std_logic_vector(31 downto 0);
in std_logic_vector(3 downto 0);
clk: in std_logic;
frame: in std_logic;
sell: out std_logic;
se12: out std_logic;
irdy: inout std_logic;
devsel: out std_logic;
trdy: inout std_logic;
inout std_logic_vector(15 downto 0) ;
inout std_logic_vector(15 downto 0));
architecture Behavioral of pci-target is
signal adr_ok, read, write: std_logic;
if clk"event and clk = "1" then
if frame = "1" then
adr_ok <= "0" ;
write <= "0" ;
if frame = "0" and adr_ok = "0" and
ad(15 downto 2) = "00000011000000" then
if cbe = "0010" then read <= "1";
adr_ok <= "1" ;
if cbe = "0011" then write <= "1" ; adr_ok <= "1" ;
elsif adr_ok = "1" and irdy = "0" and
write = "1" then
dout(15 downto 0) <= ad(15 downto 0);
ad(31 downto 0) <= "0101010101010101" &
din(15 downto 0)
when adr_ok = "1" and irdy = "0" and read = "1" ,
else "ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ";
devsel <= "0" when read = "1" or write = "1"
trdy<= "0" when read = "1" or write = "1"
se12 <= "0" ;
Одним из существенных отличий шины PCI от ISA является наличие конфигурационного пространства, в котором хранится информация о карте расширения, нужных ресурсах и пр. В этом же пространстве системный контроллер шины размещает информацию о назначаемых карте ресурсах - адресах, линиях прерывания и пр. Формат конфигурационного пространства приведен на рис. 2.24.

Рис. 2.24. Конфигурационное пространство устройства PCI
В данном блоке интерес представляют поля Device ID, Vendor ID, Class Code и Base Address Registers. Первые 3 поля сообщают контроллеру информацию о производителе (Vendor ID) и типе (остальные поля) устройства. Код класса 110000Н соответствует базовому контроллеру цифровых линий ввода-вывода. Содержимое полей Device ID и Vendor ID не имеет особенного значения, хотя оно не должно равняться нулю или 0FFFFH.
Регистр базового адреса (BAR, Base Address Register) - наиболее важная часть рассматриваемого конфигурационного пространства, поскольку его наличие в контроллере позволяет использовать автоматическое распределение ресурсов. В конфигурационном пространстве имеется 6 таких регистров, которые позволяют запросить соответственно 6 фрагмен-тов памяти и / или портов ввода-вывода. При сбросе этот регистр должен содержать число, показывающее запросы карты на аппаратные ресурсы (FFFFFFFEH кодирует запрос на 4 байта в адресном пространстве ввода-вывода). BIOS, проанализировав системную информацию, назначит карте базовый адрес (самый младший адрес в пространстве запрошенного размера) и запишет его в соответствующий регистр базового адреса. При последующей работе карта расширения должна сравнивать значение на линиях AD со значением, записанным в его базовый адрес. Поскольку шина PCI обеспечивает как минимум 32-разрядный доступ к данным, а данные адресуются побайтово, два младших бита базового адреса следует игнорировать. При запрошенных адресах в пространстве ввода-вывода младший бит числа в регистре базового адреса будет содержать единицу.
Для того чтобы карта расширения получила собственный базовый адрес, необходимо выполнить ее конфигурирование. Поскольку при инициализации базовый адрес еще неизвестен карте, возникает вопрос, каким образом может быть распознано обращение именно к этому устройству. Для организации циклов чтения и записи в конфигурационное пространство отдельных карт используется сигнал IDSEL, который подается контроллером PCI на каждую карту в отдельности (рис. 2.25).
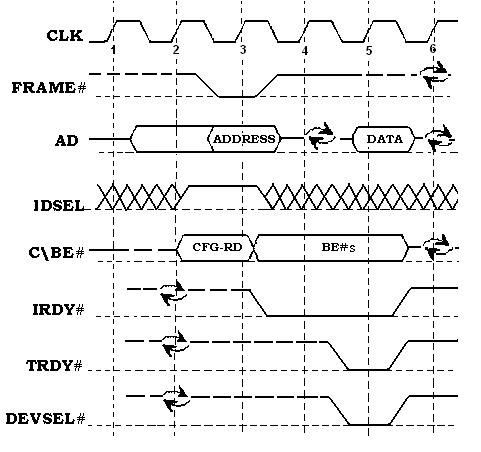
Рис. 2.25. Временная диаграмма цикла доступа к конфигурационному пространству
При разработке печатной платы контроллера PCI необходимо учитывать следующие рекомендации. Длина печатных проводников, идущих к выводам ПЛИС от контактных площадок разъема PCI, не должна превышать 1,5 дюйма, за исключением сигнала CLK, для которого длина должна составлять 2,5 ± 0,1 дюйма. Все сигналы краевого разъема должны подключаться только к одному выводу ПЛИС.
Ряд контроллеров PCI не работают с картами расширения и снимают тактовый сигнал, если эти карты не сообщают сведений о себе в конфигурационном пространстве и не поддерживают цикл Configuration Read. Более того, тип карты, указанный в конфигурационном пространстве, не должен равняться нулю или 0FFFFН. Обратите также внимание на необходимость подключения сигналов PRSNT.
Отдельным вопросом является возможность работы карт PCI по фиксированным адресам, игнорируя содержимое регистра базового адреса (в этом случае сам регистр может просто отсутствовать в ПЛИС). В этом случае, особенно при реализации контроллера PCI в CPLD, можно добиться существенной экономии ресурсов ПЛИС. Как показывает практика, такое решение в целом работоспособно, однако гарантировать надежную бесконфликтную работу карты в этом случае нельзя.



