История PCI — на пути к светлому будущему накопителей. Что такое шина PCI
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
Национальный авиационный университет
КУРСОВАЯ РАБОТА
По дисциплине: «Аппаратные средства компьютеризированных систем»
Тема: «Интерфейс периферийных устройств PCI. PCI-Express»
Выполнил: студент
Группы ФКН 501
Морозов О. Н.
Принял: профессор
Остапенко А.С.
Киев 2009
| Введение.………………………………………………………………………… | 3 |
| I. Общие сведения об интерфейсе PCI………….…..…………………………. | 4 |
| 1.1 Новейшая история PCI…………………………….….………………... | 4 |
| 1.2 PCI Express…………………..………………………………………….. | 6 |
| 1.3 Основные сведения о PCI...........…………………………….……….. 1.4 Версии шины PCI……………………………………………………….. | 10 |
| II. Принципы функционирования…………………..…….……………………… | 17 |
| 2.1 Сигналы шины PCI………………………………………………………. | 17 |
| 2.2 Разъемы шины PCI……………………………………………………….. | 20 |
| III. PSI-Express…………………………………...………………………………... | 23 |
| Выводы…………………………………………………………………………….. | 35 |
| Использованная литература………………….…………..………………………. | 36 |
ВВЕДЕНИЕ
Шина PCI (Peripheral Component Interconnect) широко используется в качестве универсальной шины ввода/вывода уже на протяжении более десяти лет, однако сегодня она уже вплотную подошла к своим пределам. Расширения стандарта PCI, типа 64-битных слотов и тактовой частоты 66 МГц или 100 МГц, слишком дороги и вряд ли успеют угнаться за растущими потребностями в высокой пропускной способности в следующие несколько лет. В качестве замены устаревающей PCI выдвинута шина ввода/вывода третьего поколения (3rd Generation IO, 3GIO), которая не так давно была переименована в PCI Express.
I . Общие сведения об интерфейсе PCI
Новейшая история PCI
Поскольку шина VLB работает синхронно с процессором, увеличение частоты процессора приводило к появлению проблем с периферией VLB. Чем быстрее должна была работать периферия, тем она дороже стоила по причине трудностей, связанных с производством высокоскоростных компонент. Лишь немногие устройства VLB поддерживали скорость выше 40 МГц.
Шина PCI обладала несколькими преимуществами по сравнению с VLB. Она была разработана в качестве промежуточного решения: PCI являлась отдельной шиной, изолированной от процессора, однако она сохранила доступ к основной памяти. Шина получила возможность асинхронной работы от процессора с номинальными частотами 25 МГц, 30 МГц и 33 МГц. По мере роста скоростей процессора частота шины PCI могла оставаться постоянной и составлять какую-то долю от шины FSB. Шина поддерживала удвоенное число слотов и/или периферийных устройств по сравнению с VLB - пять или больше, без всяких ограничений частоты или буферизации.
Другие "умные" функции облегчали использование PCI. Plug and Play позволяла производитель автоматическую конфигурацию периферии без настройки IRQ, DMA и адресов ввода/вывода через перемычки. К тому же шина поддерживала разделяемые между несколькими устройствами IRQ, а также и свою собственную систему прерываний (она скрывается за обозначениями #A, #B, #C и #D).
Наконец, управление шиной PCI (PCI bus mastering) позволяло устройствами на шине получать контроль над ней и производить прямые передачи информации без участия процессора. В результате снижались задержки и нагрузка на процессор.
Введение шины вместе с процессором Pentium, усиленное очевидными преимуществами над конкурентами, позволило PCI выиграть войну шин и стать доминирующим стандартом в 1994 году. С тех пор практически все периферийные устройства, от контроллеров жёстких дисков и звуковых карт до видеокарт и сетевых плат, базировались на шине PCI.
С распространением массивов RAID, гигабитного Ethernet и других устройств с высокой пропускной способностью на системах потребительского класса, пропускной способности PCI в 133 Мбайт/с стало не хватать. Производители чипсетов предвидели эти ограничения и вносили в свою продукцию различные изменения, чтобы снять часть нагрузки с шины PCI.
До 1997 года графическая подсистема наиболее сильно нагружала шину PCI. Выпуск вместе с чипсетом Intel 440LX ускоренного графического порта AGP (Accelerated Graphics Port) послужил двум целям: увеличить графическую производительность и убрать графические данные с шины PCI. Однако AGP явился лишь первым шагом в деле уменьшения нагрузки шины PCI. После этого производителям чипсетов пришлось переделать связь между северным и южным мостом. Старые чипсеты, типа линейки Intel 440, использовали шину PCI для связи между мостами. Шине PCI приходилось не только передавать информацию между мостами, но и обслуживать другие устройства PCI, в том числе IDE, Super I/O (параллельный и последовательный порты, PS/2), а также USB. Чтобы исправить ситуацию, Intel VIA и SiS стали использовать для связи северного и южного мостов специальную высокоскоростную линию, а затем перенесли IDE, Super I/O и USB на собственные выделенные линии к южному мосту.
Наконец, в апреле Intel анонсировала архитектуру CSA, поддерживаемую северным мостом чипсетов i875/i865, убрав гигабитный Ethernet с шины PCI.
Если AGP, CSA, Intel Hub Link, VIA V-Link и SiS MuTIOL можно назвать относительно успешными решениями в деле снятия нагрузки с шины PCI, они являются лишь промежуточными вехами.
^ PCI Express
Что касается стоимости внедрения, то новая шина призвана соответствовать уровню PCI или даже быть ниже него. Последовательная шина требует наличия меньшего числа проводников на печатной плате, облегчая дизайн платы и увеличивая его эффективность - ведь освободившееся место можно использовать для других компонентов.
Шина поддерживает совместимость с PCI на программном уровне, то есть существующие операционные системы будут загружаться без каких-либо изменений. Кроме того, конфигурация и драйверы устройств PCI Express будут совместимы с существующими PCI-вариантами.
Масштабируемость производительности достигается через повышение частоты и добавление линий к шине. PCI Express призвана обеспечить высокую пропускную способность на контакт с низким количеством служебной информации и низкими задержками. Поддерживаются несколько виртуальных каналов на один физический.
Шина может работать и в качестве соединения "точка-точка", когда устройства не разделяют общую шину.
Среди других преимуществ следует отметить:
возможность эффективно работать с различными структурами данных;
низкое энергопотребление и поддержку функций энергосбережения;
качество стратегий обслуживания;
поддержку "горячей замены" и "горячей установки" устройств;
обеспечение целостности данных и обнаружение ошибок на нескольких уровнях;
изохронную передачу данных;
узловую передачу при использовании чипов-мостов и одноранговую передачу с помощью коммутаторов;
многоуровневую технологию с поддержкой пакетной коммутации.
Архитектура PCI Express состоит из уровней, что облегчает кросс-платформенный дизайн.
В самом низу находится физический уровень (Physical Layer). Основной физический принцип связи PCI Express заключается в использовании двух дифференциальных сигналов с низким напряжением для приёма и для передачи. Встраивание сигнала данных с помощью схемы кодирования 8/10b позволяет достичь высоких скоростей передачи. Изначальная пропускная способность составляет 2,5 Гбит/с в каждом направлении, причём по мере развития кремниевых технологий скорость передачи будет расти. Возможно достижение пропускной способности 10 Гбит/с в обоих направлениях.
Одна из наиболее впечатляющих функций PCI Express заключается в возможности масштабирования скорости, используя несколько линий передачи. Физический уровень поддерживает ширину шины X1, X2, X4, X8, X12, X16 и X32 линий. Передача по нескольким линиям прозрачна для остальных слоёв.
Канальный уровень (Data Link Layer) гарантирует надёжную передачу и целостность данных для каждого пакета, переданного по связи PCI Express. Помимо использования нумерации пакетов и контрольной суммы CRC канальный уровень применяет протокол управления потоком с разрешениями на передачу, который передаёт данные только в случае готовности буфера приёма на принимающей стороне. В результате этого число повторов пакетов снижается, что позволяет более эффективно использовать пропускную способность шины. Ошибочные пакеты передаются повторно.
Уровень транзакций (Transaction Layer) создаёт пакеты и передаёт информацию от программного уровня на канальный уровень в виде отдельных транзакций. Каждый пакет имеет уникальный идентификатор, также уровень поддерживает 32-битную или расширенную 64-битную адресацию памяти. Дополнительные функции включают "no-snoop", "relaxed ordering" и установку приоритетов, что позволяет осуществлять маршрутизацию и задавать качество обслуживания QOS.
Более того, уровень транзакций знаком с четырьмя адресными пространствами: память, пространство ввода/вывода, конфигурационное пространство (три этих пространства уже существовали в спецификации PCI) и новое пространство сообщений Message Space. Последнее позволяет заменить сигналы боковой полосы частот (side-band) в спецификации PCI 2.2 и убрать все "специальные циклы" старого формата. Сюда относятся прерывания, запросы управления энергосбережением и сброс.
Наконец, программный уровень (Software Layer) отвечает за программную совместимость. Процесс инициализации и работы с устройствами шины остался неизменным по сравнению с PCI, что позволяет существующим операционным системам поддерживать PCI Express без всяких изменений. Устройства нумеруются таким образом, чтобы операционная система смогла обнаружить их и выделить необходимые ресурсы, в то время как работа с шиной построена на модели PCI загрузка-сохранение с разделяемой памятью. Впрочем, нам ещё предстоит увидеть, будет ли требоваться модификация на самом деле, поскольку "поддержка PCI Express" заявлена как одна из функций следующей операционной системы. Тонкий намёк, что предыдущие операционные системы могут и не поддерживать PCI Express.
Среди других инноваций следует отметить использование отсеков устройств, позволяющих осуществлять "горячую замену".
Мобильные пользователи не остались без внимания, поскольку для них предложен новый стандарт PCMCIA с кодовым названием NEWCARD. Форм-фактор нового стандарта таков, что карта NEWCARD практически в два раза уже одной карты CardBus. К сожалению, стандарт не предназначен для поддержки графических решений, так что пользователи ноутбуков вряд ли смогут модернизировать свои видеокарты. Однако возможности расширения относительно других устройств практически безграничны.
Поскольку PCI Express обеспечивает скорость передачи 200 Мбайт/с уже при ширине X1, шина является очень эффективным решением по отношению стоимость/число контактов.
На повестке дня находится ещё один вопрос: начнёт ли PCI Express новую войну шин с другими решениями типа PCI-X и HyperTransport? Рабочая группа PCI Express, Arapahoe, утверждает, что эти шины нацелены на другие области. RapidIO и HyperTransport были разработаны для специфических применений, в то время как PCI Express выступает в роли универсального варианта.
Вряд ли PCI Express сможет заменить HyperTransport в качестве связи между процессорами. PCI Express не хватает протокола когерентности кэшей, к тому же шина обладает более длительными задержками, чем параллельные проводники с синхронизацией по источнику. Очевидно, что AMD и nVidia бояться нечего.
PCI Express обладает великолепным потенциалом. Шина позиционируется как универсальное решение для связи компонентов платы и имеет очевидные преимущества по гибкости, что гарантирует её пригодность для широкого диапазона вариантов реализации.
Как и другие важные изменения, переход с PCI на PCI Express не случится за одну ночь. Слоты ISA жили на платах почти 10 лет, перед тем как они наконец-то исчезли. Так что не следует полагать, что периферия PCI скоро отомрёт.
Спецификации PCI Express Base 1.0a Specification и Card Electromechanical 1.0a Specification уже утверждены. Вероятно, первыми появятся видеокарты от nVidia и ATi, сопровождаемые материнскими платами на новом чипсете Grantsdale от Intel. Что касается серверной стороны рынка, Intel планирует выпустить PCI Express в паре с чипсетами Lindenhurst и Twin Castle. Будущее выглядит в радужных тонах, на что немало влияют новые форм-факторы и потенциально высокая производительность.
^
1.3 Основные сведения о PCI
Первоначально 32 проводника адрес/данные на частоте 33 МГц. Позже появились версии с 64 проводниками (используется дополнительная колодка разъема) и частотой 66 МГц.
Шина децентрализована, нет главного устройства, любое устройство может стать инициатором транзакции. Для выбора инициатора используется арбитраж с отдельно стоящей логикой арбитра. Арбитраж «скрытый», не отбирает времени - выбор нового инициатора происходит во время транзакции, исполняемой предыдущим инициатором.
Транзакция состоит из 1 или 2 циклов адреса (2 цикла адреса используются для передачи 64-битных адресов, поддерживаются не всеми устройствами, дают поддержку DMA на памяти более 4 Гб) и одного или многих циклов данных. Транзакция со многими циклами данных называется «взрывной» (burst), понимается как чтение/запись подряд идущих адресов и даёт более высокую скорость - один цикл адреса на несколько, а не на каждый цикл данных, и отсутствие простоев (на «успокоение» проводников) между транзакциями.
Специальные типы транзакций используются для обращений к конфигурационному пространству устройства.
«Взрывная» транзакция может быть временно приостановлена обеими устройствами из-за отсутствия данных в буфере или его переполнения.
Поддерживаются «расщеплённые» транзакции, когда целевое устройство отвечает состоянием «в процессе» и инициатор должен освободить шину для других устройств, захватить её снова через арбитраж и повторить транзакцию. Это делается, пока целевое устройство не ответит «сделано». Используется для сопряжения шин с разными скоростями (сама PCI и frontside процессора) и для предотвращения тупиковых ситуаций в сценарии с многими межшинными мостами.
Богатая поддержка межшинных мостов. Богатая поддержка режимов кэширования, таких, как:
Posted write - данные записи немедленно принимаются мостом и мост сразу отвечает «сделано», уже после этого пытаясь провести операцию записи на ведомой шине.
Write combining - несколько запросов на posted write, идущих подряд по адресам, соединяются в мосте в одну «взрывную» транзакцию на ведомой шине.
Prefetcing - используется при транзакциях чтения, означает выборку сразу большого диапазона адресов одной «взрывной» транзакцией в кеш моста, дальнейшие обращения исполняются самим мостом без операций на ведомой шине.
Прерывания поддерживаются либо как Message Signaled Interrupts (новое), либо классическим способом с использованием проводников INTA-D#. Проводники прерываний работают независимо от всей остальной шины, возможно разделение одного проводника многими устройствами.
Конфигурирование
PCI-устройства с точки зрения пользователя самонастраиваемы (Plug and Play). После старта компьютера системное программное обеспечение обследует конфигурационное пространство PCI каждого устройства, подключённого к шине, и распределяет ресурсы.
Каждое устройство может затребовать до семи диапазонов в адресном пространстве памяти PCI или в адресном пространстве ввода-вывода PCI.
Кроме того, устройства могут иметь ПЗУ , исполняемый код для процессоров x86 или PA-RISC , Open Firmware (системное ПО компьютеров на базе SPARC и PowerPC) или драйвер EFI .
PCI 64 - расширение базового стандарта PCI , появившееся в версии 2.1, удваивающее число линий данных, и, следовательно, пропускную способность. Cлот PCI64 является удлинённой версией обычного PCI-слота. Формально совместимость 32-битных карт с 64-битным слотами (при условии наличия общего поддерживаемого сигнального напряжения) полная, а совместимость 64-битной карты с 32-битным слотами является ограниченной (в любом случае произойдёт потеря производительности), точные данные в каждом конкретном случае можно узнать из спецификаций устройства.
Первые версии PCI64 (производные от PCI 2.1)использовали слот PCI 64-бита 5В и работали на тактовой частоте 33МГц.
PCI 66 - появившееся в версии 2.1 расширение стандарта PCI с поддержкой тактовой частоты 66МГц, также, как и PCI64 позволяет удвоить пропускную способность. Начиная с версии 2.2 использует 3.3В-слоты (32-битый вариант на ПК практически не встречается), карты имеют универсальный либо 3.3В форм-фактор. (Имелись и основанные на версии 2.1 казуистически редкие на рынке ПК 5В 66МГц решения, подобные слоты и платы были совместимы только между собой)
PCI 64/66 - комбинация двух вышеописанных технологий, позволяет учетверить скорость передачи данных по сравнению с базовым стандартом PCI , и использует 64 бита 3.3В слоты, совместимые только с универсальными и 3.3В 32-битными картами расширения. Карты стандарта PCI64/66 имеют универсальный (имеющий ограниченную совместимость с 32-битными слотами) либо 3.3В форм-фактор(последний вариант принципиально не совместим с 32-битными 33МГц слотами популярных стандартов)
В настоящее время под термином PCI64 подразумевается именно PCI64/66, поскольку 33МГц 5В 64-битные слоты не применяются уже достаточно давно.
PCI-X 1.0 - Расширение PCI64 с добавлением двух новых частот работы, 100 и 133МГц, а также механизма раздельных транзакций для улучшения производительности при одновременной работе нескольких устройств. Как правило, обратно совместима со всеми 3.3В и универсальными PCI-картами.
PCI-X карты обычно выполняются в 64-бит 3.3В формате и имеют ограниченную обратную совместимость со слотами PCI64/66, а некоторые PCI-X карты - в универсальном формате и способны работать (хотя практической ценности это почти не имеет) в обычном PCI 2.2/2.3.
В сложных случаях для того, чтобы быть полностью уверенным в работоспособности выбранной вами комбинации из мат.платы и карты расширения, случае надо посмотреть таблицы совместимости (compatibility lists) производителей обоих устройств.
PCI-X 2.0 - дальнейшее расширение возможностей PCI-X 1.0, добавлены скорости в 266 и 533МГц, а также коррекция ошибок чётности при передаче данных.(ECC). Допускает расщепление на 4 независимых 16-битных шины, что применяется исключительно во встраиваемых и промышленных системах, сигнальное напряжение снижено до 1.5В, но сохранена обратная совместимость разъёмов со всеми картами, использующими сигнальное напряжение 3.3В.
PCI-X 1066/PCI-X 2133 - проектируемые будущие варианты шины PCI-X, c результирующими частотами работы 1066 и 2133МГц соответственно, изначально предназначенные для подключения 10 и 40Гбит Ethernet адаптеров.
Вот почему в некоторых ситуациях для обеспечения стабильности работы нескольких установленных устройств необходимо ограничивать максимальную частоту работы использованной шины PCI-X (обычно это делается джамперами)
СompactPCI - стандарт для разъёмов и карт расширения, применяемый в промышленных и встраиваемых компьютерах. Механически не совместим ни с одним из "общих" стандартов.
MiniPCI - стандарт для плат и разъёмов для интеграции в ноутбуки (обычно используется для адаптеров беспроводной сети) и непосредственно на поверхность материнских плат. Также механически ни с чем кроме себя не совместим.
Типы PCI-cлотов

II. ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ
^ 2.1 Cигналы шины PCI
AD - мультиплексированная шина адреса/данных. Адрес передается по сигналу -FRAME, в последующих тактах передаются данные.
-C/BE - команда/разрешение обращения к байтам. Команда, определяющая тип очередного цикла шины (чтение-запись памяти, ввода-вывода или конфигурационное чтение-запись, подтверждение прерывания и другие) задается четырехбитным кодом в фазе адреса (по сигналу -FRAME).
-FRAME - индикатор фазы адреса (иначе - передача данных).
-DEVSEL - попытка инициатора обратиться к основной памяти.
-IRDY - готовность инициатора к обмену данными.
-LOCK - используется для установки, обслуживания и освобождения захвата ресурса на PCI.
-REQ - запрос от PCI-мастера на захват шины (для слотов 3:0).
-GNT - разрешение мастеру на использование шины.
PAR - общий бит паритета для линий AD и C/BE.
-ParityER - сигнал об ошибке паритета (от устройства, ее обнаружившего).
-RST - сброс всех регистров в начальное состояние.
IDSEL - выбор устройства в циклах конфигурационного считывания и записи.
-SERR - системная ошибка, активизируется любым устройством PCI и вызывает NMI.
-REQ64 - запрос на 64-битный обмен.
-ACK64 - подтверждение 64-битного обмена.
-INTR A,B,C,D - линии запросов прерывания, циклически сдвигаются в слотах и направляются на доступные линии IRQ с помощью конфигурационных регистров. Запрос по низкому уровню позволяет использовать одну линию несколькими источниками.
Clock - тактовая частота шины.
Test Clock, -TSTRES,
TestDO, TestDI - сигналы для тестирования адаптеров по интерфейсу JTAG (на системной плате обычно не задействованы).
TSTMSLCT - перевод в режим тестирования.
-TRDY - готовность целевого устройства к обмену данными.
-STOP - запрос целевого устройства к инициатору на останов текущей транзакции.

^ 2.2 Разъемы шины PCI
| Ряд В | № | Ряд А | Ряд В | № | Ряд А |
|
| - 12 В | 1 | -TSTRES | GND/Ключ | 51* | GND/Ключ |
|
| Test Clock | 2 | + 12B | AD 8 | 52 | -C/BE 0 |
|
| GND | 3 | TSTMSLCT | AD 7 | 53 | + 3.3B |
|
| Test DO | 4 | Test DI | + 3.3B | 54 | AD 6 |
|
| + 5В | 5 | + 5B | AD 5 | 55 | AD 4 |
|
| + 5B | 6 | -INTR A | AD 3 | 56 | GND |
|
| -INTR B | 7 | -INTR C | GND | 57 | AD 2 |
|
| -INTR D | 8 | + 5B | AD 1 | 58 | AD 0 |
|
| -PRSNT 1 | 9 | Reserved | +V I/O | 59 | +V I/O |
|
| Reserved | 10 | + V I/O | -ACK64 | 60 | -REQ64 |
|
| -PRSNT 2 | 11 | Reserved | + 5B | 61 | + 5B |
|
| GND/Ключ | 12* | GND/Ключ | + 5B | 62 | + 5B |
|
| GND/Ключ | 13* | GND/Ключ | Конец 32-битного разъема |
|||
| Reserved | 14 | Reserved | ||||
| GND | 15 | -RST | Reserved | 63 | GND |
|
| Clock | 16 | +V I/O | GND | 64 | -C/BE 7 |
|
| GND | 17 | -GNT | -C/BE 6 | 65 | -C/BE 5 |
|
| -REQ | 18 | GND | -C/BE 4 | 66 | +V I/O |
|
| +V I/O | 19 | Reserved | GND | 67 | PAR64 |
|
| AD 31 | 20 | AD 30 | AD 63 | 68 | AD 62 |
|
| AD 29 | 21 | + 3.3B | AD 61 | 69 | GND |
|
| GND | 22 | AD 28 | +V I/O | 70 | AD 60 |
|
| AD 27 | 23 | AD 26 | AD 59 | 71 | AD 58 |
|
| AD 25 | 24 | GND | AD 57 | 72 | GND |
|
| + 3.3B | 25 | AD 24 | GND | 73 | AD 56 |
|
| -C/BE 3 | 26 | IDSEL | AD 55 | 74 | AD 54 |
|
| AD 23 | 27 | +3.3B | AD 53 | 75 | +V I/O |
|
| GND | 28 | AD 22 | GND | 76 | AD 52 |
|
| AD 21 | 29 | AD 20 | AD 51 | 77 | AD 50 |
|
| AD 19 | 30 | GND | AD 49 | 78 | GND |
|
| +3.3B | 31 | AD 18 | +V I/O | 79 | AD 48 |
|
| AD 17 | 32 | AD 16 | AD 47 | 80 | AD 46 |
|
| -C/BE 2 | 33 | +3.3B | AD 45 | 81 | GND |
|
| GND | 34 | -FRAME | GND | 82 | AD 44 |
|
| -IRDY | 35 | GND | AD 43 | 83 | AD 42 |
|
| +3.3B | 36 | -TRDY | AD 41 | 84 | + V I/O |
|
| -DEVSEL | 37 | GND | GND | 85 | AD 40 |
|
| GND | 38 | -STOP | AD 39 | 86 | AD 38 |
|
| -Lock | 39 | +3.3B | AD 37 | 87 | GND |
|
| -ParityER | 40 | SDONE | +V I/O | 88 | AD 36 |
|
| +3.3B | 41 | -SBOFF | AD 35 | 89 | AD 34 |
|
| -SysERR | 42 | GND | AD 33 | 90 | GND |
|
| +3.3B | 43 | PAR | GND | 91 | AD 32 |
|
| -C/BE 1 | 44 | AD 15 | Reserved | 92 | Reserved |
|
| AD 14 | 45 | +3.3B | Reserved | 93 | GND |
|
| GND | 46 | AD 13 | GND | 94 | Reserved |
|
| AD 12 | 47 | AD 11 | Конец 64-битного разъема |
|||
| AD 10 | 48 | GND | ||||
| GND | 49 | AD 9 | ||||
| GND/Ключ | 50* | GND/Ключ | ||||
*12, 13 - ключ для 3.3В
*50, 51 - ключ для 5В
Определены два типа устройств стандарта PCI - целевое и ведущее. Целевое устройство воспринимает команды и реагирует на запросы ведущего. Ведущее устройство представляет собой более “интеллектуальное” устройство, которое может производить обработку независимо от шины или других устройств. Ведущее устройство разделяет шину с основным процессором и целевыми устройствами. Кроме того, оно может выступать целевым устройством для других ведущих устройств. Определение стандарта PCI требует 47 контактов только для целевого и 49 контактов для ведущего. Это число представляется невероятно малым, если учесть потенциальные возможности шины и тот факт, что сюда включены функции передачи данных и адресации, управления интерфейсом, арбитража, а также системные функции. Однако спецификация предусматривает до 120 соединений для стандартной 32-битовой платы и 184 для 64-битовых плат. В основе стандарта лежит мультиплексирование, при котором через одни и те же контакты передаются разнотипные сигналы. Адреса и данные мультиплексируются на одни и те же контакты, поэтому одиночная передача по шине PCI состоит из двух фаз: фаза адресации сопровождается одной или несколькими фазами данных. Ведущее устройство выдает адрес и обращается к конкретному устройству на шине. Выбранное устройство переходит в соответствующий режим для приема данных или инструкций, а затем ведущее устройство посылает пакет данных по тем же контактам, которые использовались для вызова. После определения адреса ведущее устройство может посылать данные без повторения адресации, так как целевое устройство уже выбрано. Отметим, что передача данных может включать в себя и чтение и запись информации.
Для PCI определяются три физических адресных пространства: памяти, ввода-вывода и конфигурации. Адресация памяти и ввода-вывода аналогична применяемой во всех шинах. Адресное пространство конфигурации PCI предназначено для входящего в определение стандарта средства автоматического аппаратного конфигурирования.
Еще одной интересной особенностью шины, способствующей её упрощению, является распределенное дешифрирование адреса, когда каждое подключенное к локальной шине PCI устройство производит дешифрирование адреса самостоятельно. Благодаря этому становятся ненужными схемы централизованного дешифрирования адреса и сигналы выбора устройств, за исключением одного сигнала, предназначенного для конфигурирования.
III. PSI-Express
Любая компьютерная технология проходит свой путь от рождения, триумфа к свалке истории. Все бы ничего, да каждое очередное нововведение, как правило, чревато серьезным перетряхиванием системных блоков и неопределенностью в умах пользователей – пора или еще подождать с апгрейдом? Тем более огромными кажутся все новшества, которые свалятся на головы покупателей в нынешнем году. Такого всестороннего разрушительного действия на основы платформы не было уже давно - сменятся процессорные разъемы (у Intel настанет время Socket 775, у AMD, соответственно, Socket 939); к концу года действительно новой будет называться система лишь с 240-контактными модулями DDR2; вдогонку ко всему этому близится появление новых форм-факторов самих плат – BTX. Но самым радикальным все же станет низвержение старых привычных элементов ландшафта системной платы – разъемов PCI и AGP, которым приходит время сказать последнее "прости-прощай".
Новое поколение технологий приносит новые скорости и новые технологические решения. Правда, на деле случалось не раз, что революционные нововведения оказывались не всегда своевременными и не такими уж полезными, как красиво заявлялось при их выпуске. Традиционно, отдуваться за эксперименты приходится конечному покупателю. Примеров самых передовых, но неоцененных или невостребованных технологий можно привести множество – шина EISA, память RDRAM, слоты AMR/CNR и многое другое.
Не касаясь тупиковых ветвей эволюции ПК, сегодня стоит поговорить о своевременности внедрения новых технологий на примере шины PCI Express. Сегодня можно с уверенностью сказать, что от перехода на этот шинный стандарт никуда не деться. Попробуем рассмотреть ключевые особенности новоявленной шины, ее сходства и отличия от распространенных сейчас PCI и AGP.
Немного истории
Первые разработки шины PCI, стартовавшие в начале 90-х годов, были призваны избавиться от множества присутствовавших на тот момент несовместимых шинных интерфейсов – VLB (VESA Local Bus), EISA, ISA и Micro Channel. Наряду с этим преследовалась цель избавиться от тяжкого наследия фрагментированной шины ISA и впервые добиться соединений класса "чип-чип".

На момент появления в 1993 году базовой версии шины Peripheral Component Interconnect (PCI) - IEEE P1386.1, предусматривались революционные усовершенствования: расширение шины данных до 32 бит, поддержка адресации до 4 ГБ данных (32 бита), а также использование режима синхронного обмена данными. По тем временам тактовая частота шины 33 МГц удовлетворяла условиям работы с периферией в настольных и серверных системах, все были довольны. Последовавший за этим резкий скачок тактовых частот процессоров и памяти привел к увеличению тактовой частоты PCI до 66 МГц, хотя, тактовые частоты процессоров за этот же период скакнули с 33 МГц до 3,0+ ГГц. Все последующие варианты PCI – AGP, PCI-X, MiniPCI, CardBus, несмотря на привнесение определенных дополнений, например, иных форм-факторов разъемов, новых сигнальных уровней и даже передачи данных по фронтам импульса (Double Data Rate/ Quadruple Data Rate), тем не менее, несли в себе ограничения, накладываемые самой топологией интерфейса.
Возможности наращивания пропускной способности шины PCI за счет увеличения тактовой частоты без усложнения схем разводки и соответствующего адекватного удорожания к настоящему времени исчерпаны полностью. А ведь на очереди появились такие актуальные интерфейсы, как 1/10 Gigabit Ethernet, IEEE 1394B, которые полностью выбирают пропускную возможность шины одним устройством и даже выходят за эти рамки. PCI душит рост скорости периферии, критичными становятся ограничения по числу сигнальных контактов шины, торможение процессов реального времени и требования по энергосбережению современных ПК. Если вспомнить наиболее производительные версии шины PCI, например, серверную PCI-X и графическую AGP, то в этом случае мы упираемся в укорачивание проводников шины за счет высокой частоты, требование к установке своего контроллера на каждый слот и достаточно высокую стоимость ее реализации.
Грядет тотальное торжество последовательных шин
Итого, параллельные шины себя исчерпали, рано или поздно взоры разработчиков должны были обратиться в сторону последовательных. Так оно и есть, в результате чего практически все современные индустриальные интерфейсы к настоящему времени перебрались на такой принцип обмена данными. Взгляните на приведенную ниже таблицу: речь идет не только о сетевых интерфейсах, которым на роду написано быть последовательными; все остальные ключевые шины уже имеют последовательную природу.

Между прочим, внешние интерфейсы уже давно перебрались на последовательную топологию, и в самых своих свежих реализациях – USB 2.0, IEEE1394b, показывают скорости, которые немыслимы для параллельных соединений. С этой точки зрения шина PCI в наших компьютерах действительно, выглядит своеобразным анахронизмом.
Особенности PCI Express

Архитектуру PCI Express можно рассматривать послойно, в сравнении с адресной моделью PCI. Конфигурация PCI Express является стандартной для устройств, определенных plug-and-play спецификациями PCI: программный уровень генерирует запросы чтения/записи, уровень транзакций транспортирует эти запросы к периферийным устройствам с помощью разделенного пакетного протокола. Для поддержания высокой производительности шины соединительный (link) уровень добавляет пакетам очередность и CRC; базовый физический уровень состоит из двойного симплексного канала, осуществляющего функции приемной и передающей пары. Таким образом, исходная скорость 2,5 Гб/с в каждом направлении позволяет говорить о создании дуплексного коммуникационного канала производительностью до 200 МБ/с, что в четыре раза превышает возможности классической шины PCI.
Рассматривая процессы, протекающие в шине на сигнальном уровне, нельзя не отметить уникальные плюсы PCI Express - значительное снижение затухания в линиях передачи и повышенная чувствительность приемной части интерфейса. Из чего напрашивается вывод о менее критичных требованиях к импедансу входных цепей, а также возможность увеличения длины разводки проводников шины - в нынешней версии стандарта PCI-E они лимитируются 12 дюймами для системных плат, 3,5 дюймами для контроллеров и 15 дюймами для межчиповых соединений. При этом не предъявляется никаких дополнительных требований к технологии разводки печатной платы: могут использоваться как обычные 4-слойные PCB толщиной 0,062 дюйма, так и варианты с шестью и более слоями. 
Теоретически, требования, выдвигаемые стандартом PCI Express, с легкостью могут быть адаптированы для нужд устройств любого уровня – от мобильного телефона до сервера уровня предприятия, а также, в перспективе, могут быть переложены для применения других физических типов носителей. Именно такая гибкость и необходима для интерфейса, собирающегося прослужить стандартом ближайшее обозримое будущее.
Использование новых разъемов и других конструктивных возможностей, оговоренных спецификациями нового стандарта, позволяет говорить об увеличении энергопотребления конечных контроллеров до 75 Вт (при токе до 5,5 А)! 
Такие мощные контроллеры потребуют дополнительных мер по отводу тепла из корпуса, зато отпадет нужда в подводке разъемов дополнительного питания, которые так характерны для нынешнего поколения видеокарт AGP 8x.

Системы питания компьютеров с поддержкой разных вариантов PCI Express отличаются от привычных нам спецификаций ATX12 и, скорее, схожи с требованиями, предъявляемыми к питанию серверных систем. Так, привычный 20-контактный разъем питания ATX удлиняется и в нем появляются четыре дополнительных контакта, как раз для усиления силовых шин +12 В, 5,0 В и +3,3 В. Соответственно, до 75 Вт повышаются ограничения на питание одного слота в BIOS. При этом нижняя граница мощности для блоков питания устанавливается на уровне примерно 300 Вт. Словом, хотя изменения в цепях питания и не носят такой радикальный характер, как при переходе с AT на ATX, с мыслью о неминуемом апгрейде БП придется свыкнуться.

^ Варианты PCI Express: их будет много
Версии PCI Express будут внедряться в зависимости от ставящихся перед интерфейсом задач и типом устройства. Например, серверы, где востребована максимальная пропускная способность, будут оборудованы максимальным количеством слотов PCI Express с максимальными показателям. В то же время, для нужд ноутбуков в большинстве случаев будет достаточно архитектуры PCI Express x1. Для настольных ПК и рабочих станций понадобится комбинация из различных вариантов реализации шины.

Совершенно новые требования выдвигаются к механическим показателям PCI Express. Для того, чтобы периферийные платы не имели возможности вывалиться из слота при вибрации или транспортировке, разработаны повышенные требования к защелкам и крепежу разъемов PCI Express.
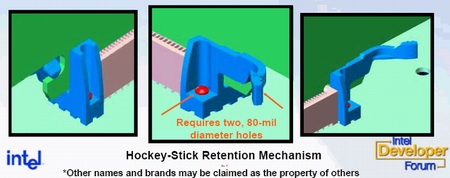
Несмотря на то, что новый стандарт дает некую свободу конечным производителям при разработке крепежа, жестко оговоренными остаются следующие требования: энергопотребление – не более 75 Вт, вес – не более 350 граммов, высота – не более 115,15 мм.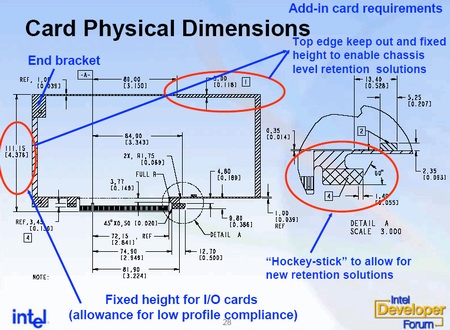
Конечно, под такими монстрами прозрачно подразумеваются графические карты с интерфейсом PCI Express 16x; во всех других случаях требования к крепежу и другим характеристикам контроллеров значительно скромнее.
Особняком стоит реализация PCI Express для мобильных устройств в виде стандарта ExpressCard. Первыми поддержку модулей этого подстандарта получат ноутбуки и миниатюрные настольные ПК, хотя, уже известны случаи представления концепций серверных плат с разъемом ExpressCard. основное преимущество применения таких модулей - подключение периферии практически без нужды использования крепежного инструмента, а также инсталляции дополнительных драйверов. Технология ExpressCard заменит собой все устаревшие параллельные шины, в результате останутся только три современных интерфейса - PCI Express, USB 2.0 и FireWire.

В настоящее время разработано два форм-фактора модулей ExpressCard – ExpressCard/34 (ширина 34 мм) и ExpressCard/54 (ширина 54). Оба модуля имеют высоту 5 мм, как у стандарта PC Card Type II; длина модулей 75 мм, что на 10,6 мм меньше, чем у PC Card. При этом, модули ExpressCard/34 и ExpressCard/54 обладают одинаковым интерфейсом. Каждый слот под модули ExpressCard может обслуживать шину PCI Express x1.
Преимущества PCI Express
Сравнивая возможности господствовавшей многие годы параллельной шины PCI и архитектуру PCI Express, можно выделить пять наиболее значимых преимуществ последней:
^ Высокая производительность – повышение пропускной способности версии x1 как минимум вдвое по сравнению с PCI, возможность линейного наращивания производительности путем линейного расширения шины. Помимо этого, PCI Express является реально дуплексной шиной.
^ Упрощение разводки периферии – стандартизация там, где ранее использовались всевозможные варианты PCI - AGP, PCI-X и др.; снижение комплексных затрат на разработку и внедрение систем.
^ Уровневая архитектура – основные затраты на развитие PCI Express в дальнейшем ложатся лишь на разработку соответствующей обвязки, можно экономить на возможности работы с прежним программным обеспечением.
^ Следующее поколение периферии – PCI Express позволяет реализовать новые возможности обмена данными и мультимедийным контентом за счет изохронной природы передачи (т.е. разнесения отдельных частей сигнала по времени).
^ Простота использования – производить апгрейд и доработку систем устройствами PCI Express станет значительно легче. Теперь появится возможность использовать PCI Express карты с "горячим" подключением.
В заключение попробуем ответить на заданный в начале вопрос – действительно, своевременно ли появление PCI Express? Тональность ответа явно будет разной в зависимости от того, кому задан вопрос – разработчику, производителю или конечному покупателю. В первом случае, ответ будет в большинстве своем восторженно-утвердительный., ведь именно разработчиков железа порадует унификация сигнальных уровней и топологии большинства шин системы! Производители системных плат, видеокарт и прочей обвязки ПК, скорее всего, с досадой припомнят Конфуция с его замечанием о жизни в эпоху перемен, ведь им теперь приходится наперед просчитывать баланс спроса на системы с новой, старой и смешанной архитектурой, а это влечет за собой неуверенность в правильности выбранной стратегии в плане маркетинга и логистики. С другой стороны, "мутная водичка" – подходящий момент для того, чтобы изменить расстановку сил и выбиться в лидеры.
Наверно, в самой странной ситуации останутся потребители, следившие за последними разработками и прикупившие себе самые продвинутые версии видеокарт с шиной AGP 8x. Вот уж кого уверяли, что круче некуда и это надолго! Да, возможности этого интерфейса действительно, до конца так и не были использованы, но время не ждет, на горизонте – новая 16x вершина, которую, вроде бы, обещают надолго. Слабым, но утешением могут служить два тезиса: во-первых, PCI Express – это действительно надолго; во-вторых, на протяжении 2004 года никто от старых добрых слотов отказываться не спешит, в большинстве своем новые платы будут обладать всем набором шин, включая PCI, AGP и PCI Express. Время для того, чтобы состариться, у ваших AGP 8x еще есть.
ВЫВОДЫ
1. Рассмотрен интерфейс PCI - шины для подсоединения периферийных устройств.
2. Проанализированы разные спецификации PCI и их внутреннее устройство.
3. Показано, что новая версия PCI-Express 2.0, а также разрабатываемая в данное время, PCI-Express 3.0 являются универсальными интерфейсами и будут успешно использоваться в будущем как на персональных компьютерах, так и других автоматических системах, где необходима высокая скорость.
4. Рассмотрены преимущества PCI-Express перед её предшественницей PCI, а именно: высокая производительность, упрощение разводки периферии, уровневая архитектура, простота использования
ИСПОЛЬЗОВАННАЯ ЛИТЕРАТУРА:
1. Михаил Гук
“Карманная энциклопедия. Аппаратные средства IBM PC”
Второе издание. Санкт-Петербург 1997. Изд. “Питер Пресс”
2. Питер Нортон, Кори Сандлер, Том Баджет “ПК изнутри”
Изд. “Бином” Москва 1995
3. “Мир ПК” 2’97 с.178 – 180
Статья Л.Подбережного “Интелвидение будущего”
5. “PC magazine” № 1 1994 с.61 - 68
Статья Д.Роуэлла “Локальная шина PCI”
Итак, переходим к самому интересному. Что же находится на сегодняшний день внутри большинства наших компьютеров? Естественно, шина PCI. Другой вопрос, почему именно эта шина. Попробуем разобраться.
Итак, разработка шины PCI началась весной 1991 года как внутренний проект корпорации Intel (Release 0.1). Специалисты компании поставили перед собой цель разработать недорогое решение, которое бы позволило полностью реализовать возможности нового поколения процессоров 486/Pentium/P6 (вот уже половина ответа). Особенно подчеркивалось, что разработка проводилась "с нуля", а не была попыткой установки новых "заплат" на существующие решения. В результате шина PCI появилась в июне 1992 года (R1.0). Разработчики Intel отказались от использования шины процессора и ввели еще одну "антресольную" (mezzanine) шину.
Благодаря такому решению шина получилась, во-первых, процессоро-независимой (в отличие от VLbus), а во-вторых, могла работать параллельно с шиной процессора, не обращаясь к ней за запросами. Например, процессор работает себе с кэшем или системной памятью, а в это время по сети на винчестер пишется информация. Просто здорово! На самом деле идиллии, конечно, не получается, но загрузка шины процессора снижается здорово. Кроме того, стандарт шины был объявлен открытым и передан PCI Special Interest Group, которая продолжила работу по совершенствованию шины (в настоящее время доступен R2.1), и в этом, пожалуй, вторая половина ответа на вопрос "почему PCI?"
Основные возможности шины следующие.
При разработке шины в ее архитектуру были заложены передовые технические решения, позволяющие повысить пропускную способность.
Шина поддерживает метод передачи данных, называемый "linear burst" (метод линейных пакетов). Этот метод предполагает, что пакет информации считывается (или записывается) "одним куском", то есть адрес автоматически увеличивается для следующего байта. Естественным образом при этом увеличивается скорость передачи собственно данных за счет уменьшения числа передаваемых адресов.
Шина PCI является той черепахой, на которой стоят слоны, поддерживающие "Землю" - архитектуру Microsoft/Intel Plug and Play (PnP) PC architecture. Спецификация шины PCI определяет три типа ресурсов: два обычных (диапазон памяти и диапазон ввода/вывода, как их называет компания Microsoft) и configuration space - "конфигурационное пространство".
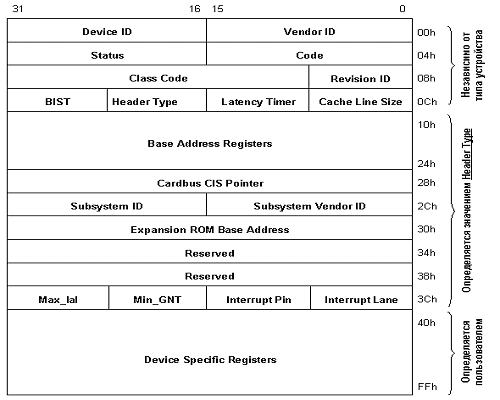
Конфигурационное пространство состоит из трех регионов:
- заголовка, независимого от устройства (device-independent header region);
- региона, определяемого типом устройства (header-type region);
- региона, определяемого пользователем (user-defined region).
В заголовке содержится информация о производителе и типе устройства - поле Class Code (сетевой адаптер, контроллер диска, мультимедиа и т.д.) и прочая служебная информация.
Следующий регион содержит регистры диапазонов памяти и ввода/вывода, которые позволяют динамически выделять устройству область системной памяти и адресного пространства. В зависимости от реализации системы конфигурация устройств производится либо BIOS (при выполнении POST - power-on self test), либо программно. Базовый регистр expansion ROM аналогично позволяет отображать ROM устройства в системную память. Поле CIS (Card Information Structure) pointer используется картами cardbus (PCMCIA R3.0). С Subsystem vendor/Subsystem ID все понятно, а последние 4 байта региона используются для определения прерывания и времени запроса/владения.
PCI - шина
PCI (Peripheral Component Interconnect bus) - шина для подсоединения периферийных устройств. Стала массово применяться для Pentium-систем, но используется и с 486 процессорами. Частота шины от 20 до 33 МГц, теоретически максимальная скорость 132/264 Мбайт/с для 32/64 бит. В современных материнских платах частота на шине PCI задается как 1/2 входной частоты процессора, т.е при частоте 66 MHz на PCI будет 33 MHz, при 75 MHz - 37.5 MHz.
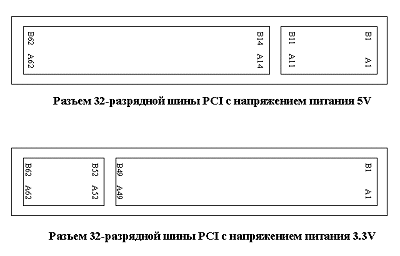
Имеет версии с питанием 5V, 3.3V и универсальную (с переключением линий +VI/O c 5V на 3,3V). Ключами являются пропущенные ряды контактов 12, 13 и 50, 51. Для слота с питанием 5V ключ расположен на месте контактов 50, 51, для 3,3 В - 12, 13, а для универсального - два ключа: 12, 13 и 50,51. 32-битный слот заканчивается контактами А62/В62, 64-битный - А94/В94.
Слот PCI самодостаточен для подключения любого контроллера на системной плате может сосуществовать с любой из других шин ввода-вывода.
Шина PCI - первая шина в архитектуре IBM PC, которая не привязана к этой архитектуре. Она является процессорно-независимой и применяется, например, в компьютерах Macintosh.
В отличие от остальных шин, компоненты расположены на левой поверхности плат PCI-адаптеров. По этой причине крайний PCI-слот обычно разделяет использование посадочного места с соседним ISA-слотом (Shared slot).
Процессор через так называемые мосты (PCI Bridge) может быть подключен к нескольким каналам PCI, обеспечивая возможность одновременной передачи данных между независимыми каналами PCI.
Автоконфигурирование устройств (выбор запросов прерывания, каналов DMA) поддерживается средствами BIOS материнской платы по образу и подобию стандарта Plug & Play.
Стандарт PCI определяет для каждого слота конфигурационное пространство размером до 256 восьмибитных регистров, не приписанных ни к пространству памяти, ни к пространству ввода-вывода. Доступ к ним осуществляется по специальным циклам шины Configuration Read и Configuration Write, вырабатываемым контроллером при обращении процессора к регистрам контроллера шины PCI, расположенным в его пространстве ввода-вывода.
На PCI определены два основных вида устройств - инициатор (по ГОСТ - задатчик), т.е. устройство, получившее от арбитра шины разрешение на захват ее и устройство назначения, цель (target) с которым инициатор выполняет цикл обмена данными.
Поддержка "горячей" замены PCI устройств, называемой в стандарте как PCI Hot-Plug. Ввод этой функции позволит добавлять/изымать PCI платы без выключения компьютера. Такая возможность особенно необходима для серверных платформ
Система управления энергопотреблением для устройств на шине PCI. Позволяет управлять энергопотреблением как для внешних PCI плат так и для встроенных на материнской плате устройств. Механизм управления подстроен под стандарт ACPI для облегчения управления энергопотреблением PCI устройств со стороны операционной системы.
Дополнены и переработаны требования к конструктивной реализации PCI плат.
Сигналы шины PCI
Знак - (минус) перед названием сигнала означает, что активный уровень этого сигнала логический ноль, обозначение {XX:0} означает группу сигналов с номерами от 0 до XX.
AD {31:0} - мультиплексированная шина адреса/данных. Адрес передается по сигналу - FRAME, в последующих тактах передаются данные.
-C/ BE {3:0} - команда/разрешение обращения к байтам. Команда, определяющая тип очередного цикла шины (чтение-запись памяти, ввода/вывода или чтение/запись конфигурации, подтверждение прерывания и другие) задается четырехбитным кодом в фазе адреса по сигналу - FRAME.
-FRAME - индикатор фазы адреса (иначе - передача данных).
-DEVSEL - выбор инициатором устройства назначения.
-IRDY - готовность инициатора к обмену данными.
-TRDY - готовность устройства назначения к обмену данными.
-STOP - запрос устройства назначения к инициатору на останов текущей транзакции.
-LOCK - используется для установки, обслуживания и освобождения захвата ресурса на PCI.
-GNT {3 0} - разрешение мастеру на использование шины.
PAR - общий бит четности для линий AD {31:0} и C/BE {3:0}.
-ParityER - сигнал об ошибке по четности (от устройства, ее обнаружившего).
-RST - сброс всех устройств.
IDSEL - выбор устройства назначения в циклах считывания и записи конфигурации.
-SERR - системная ошибка, активизируется любым устройством PCI и вызывает емаскируемое прерывание процессора (NMI).
-REQ64 - запрос на 64-битный обмен.
-ASK64 - подтверждение 64-битного обмена.
-INTR A,B,C,D - линии запросов прерывания, направляются на доступные линии IRQ BIOS компьютера. Запрос по низкому уровню допускает разделяемое использование линий прерывания.
Clock - сигнал синхронизации на тактовой частоте шины.
Test Clock, -TSTRES, TestDO, TestDI - сигналы для тестирования адаптеров по интерфейсу JTAG (на системной плате обычно не задействованы).
TSTMSLCT - перевод в режим тестирования.
Разъем шины PCI
| Ряд В | Номер | Ряд А | Ряд В | Номер | Ряд А |
| -12 В | 1 | -TSTRES | -C / BE 3 | 26 | IDSEL |
| Test Clock | 2 | +12 B | AD 23 | 27 | +3,3 B |
| GND | 3 | TSTMSLCT | GND | 28 | AD 22 |
| Test DO | 4 | Test DO | AD 21 | 29 | AD 20 |
| +5 B | 5 | +5 B | AD 19 | 30 | GND |
| +5 B | 6 | -INTR A | +3,3 B | 31 | AD 18 |
| -INTR B | 7 | -INTR C | AD 17 | 32 | AD 16 |
| -INTR D | 8 | +5 B | -C / BE 2 | 33 | +3,3 B |
| -PRSNT 1 | 9 | Reserved | GND | 34 | -FRAME |
| Reserved | 10 | +VI / O | -IRDY | 35 | GND |
| -PRSNT 2 | 11 | Reserved | +3,3 B | 36 | -TRDY |
| GND / Ключ | 12 | GND /Ключ | -DEVSEL | 37 | GND |
| GND / Ключ | 13 | GND /Ключ | GND | 38 | -STOP |
| Reserved | 14 | Reserved | -Lock | 39 | +3,3 B |
| GND | 15 | -RST | ParityER | 40 | SDONE |
| Clock | 16 | +VI / O | +3,3 B | 41 | -SBOFF |
| GND | 17 | -GNT | SysERR | 42 | GND |
| -REQ | 18 | GND | +3,3 B | 43 | PAR |
| +V I/O | 19 | Reserved | -C / BE 1 | 44 | AD 15 |
| AD 31 | 20 | AD 30 | AD 14 | 45 | +3,3 B |
| AD 29 | 21 | +3,3 B | GND | 46 | AD 13 |
| GND | 22 | AD 28 | AD 12 | 47 | AD 11 |
| AD 27 | 23 | AD 26 | AD 10 | 48 | GND |
| AD 25 | 24 | GND | GND | 49 | AD 9 |
| +3,3 B | 25 | AD 24 | GND / Ключ | 50** | GND / Ключ |
| GND /Ключ | 51**** | GND / Ключ | GND | 73 | AD 56 |
| AD 8 | 52 | -C / BE 0 | AD 55 | 74 | AD 54 |
| AD 7 | 53 | +3,3 B | AD 53 | 75 | +VI / O |
| +3,3 B | 54 | AD 6 | GND | 76 | AD 52 |
| AD 5 | 55 | AD 4 | AD 51 | 77 | AD 50 |
| AD 3 | 56 | GND | AD 49 | 78 | GND |
| GND | 57 | AD 2 | +VI / O | 79 | AD 48 |
| AD 1 | 58 | AD 0 | AD 47 | 80 | AD 46 |
| + VI / O | 59 | +VI / O | AD 45 | 81 | GND |
| -ACK 64 | 60 | -REQ64 | GND | 82 | AD 44 |
| +5 B | 61 | +5B | AD 43 | 83 | AD 42 |
| +5 B | 62 | +5B | AD 41 | 84 | +VI / O |
| Конец 32-битного разъема | GND | 85 | AD 40 | ||
| AD 39 | 86 | AD 38 | |||
| Reserved | 63 | GND | AD 37 | 87 | GND |
| GND | 64 | -C / BE 7 | +VI / O | 88 | AD 36 |
| -C / BE | 65 | - C / BE 5 | AD 35 | 89 | AD 34 |
| -C / BE | 66 | + VI / O | AD 33 | 90 | GND |
| GND | 67 | PAR 64 | GND | 91 | AD 32 |
| AD 63 | 68 | AD 62 | Reserved | 92 | Reserved |
| AD 61 | 69 | GND | Reserved | 93 | GND |
| +VI / O | 70 | AD 60 | GND | 94 | Reserved |
| AD 59 | 71 | AD 58 | Конец 64-битного разъема | ||
| AD 57 | 72 | GND | |||
*12, 13 - ключ для 3,3V
**50,51 - ключ для 5V
Циклы шины
По сигналам C/BE (от C/BE3 до C/BE0) во время фазы передачи адреса определяется тип цикла передачи данных.
| C/BE | Команда |
| 0000 | Interrupt Acknowledge (подтверждение прерывания) |
| 0001 | Special Cycle (специальный цикл) |
| 0010 | I/O Read (чтение порта) |
| 0011 | I/O Write (запись в порт) |
| 0100 | Reserved (резервировано) |
| 0101 | Reserved (резервировано) |
| 0110 | Memory Read (чтение памяти) |
| 0111 | Memory Write (запись в память) |
| 1000 | Reserved (резервировано) |
| 1001 | Reserved (резервировано) |
| 1010 | Configuration Read (чтение конфигурации) |
| 1011 | Configuration Write (запись конфигурации) |
| 1100 | Multiple Memory Read (множественное чтение памяти) |
| 1101 | Dual Address Cycle (двойной цикл адреса) |
| 1110 | Memory-Read Line (чтение памяти) |
| 1111 | Memory Write and Invalidate (запись в память и проверка) |
Подтверждение прерывания (0000)
Контроллер прерываний автоматически распознает сигнал INTA и реагирует на него передачей вектора прерывания по шине AD.
Специальный цикл (0001)
Чтение порта (0010) и запись в порт (0011)
Порты ввода/вывода на шине PCI могут быть 8 или 16-ти разрядными, хотя собственно стандарт на шину PCI позволяет иметь 32-х разрядное адресное пространство. Это вызвано тем, что на компьютерах с архитектурой Intel x86, адрес порта может иметь не более 16 разрядов. Пока и 16-ти разрядный адрес порта не может быть использован, так как карты на шине ISAC:\www\doc2html\work\bestreferat-93864-13927654724498\input\isabus.htm могут декодировать только 10 разрядов.
Адресное пространство конфигурации доступно по адресам портов 0x0CF8 (Адрес) и 0x0CFC (Данные), причем адрес должен быть записан первым.
Чтение памяти (0110) и запись в память (0111)
По шинам AD передается адрес двойным словом (четыре байта). Сигналы AD0 и AD1 декодировать не требуется. Истинность данных определяется сигналами C/BE.
Чтение конфигурации (1010) и запись конфигурационных данных (1011)
Эти операции выполняются для конфигурационного пространства PCI карты. Размер области конфигурации составляет 256 байт, причем читать/записывать в нее можно только в 32-х разрядной сетке, т.е. двойными словами. Поэтому AD0 и AD1 должны быть установлены в 0, AD2-7 содержать адрес двойного слова, AD8-10 используются для выбора адресуемого устройства, а оставшиеся шины адреса игнорируются.
Двойной цикл адреса (1101)
Двойной цикл адреса необходим в том случае, если необходимо передать 64-х разрядный адрес в версии PCI с 32-х разрядной адресной сетке. В первом цикле передаются четыре младших байта адреса, затем четыре старших байта. Во втором цикле необходимо также передать команду, определяющую тип устройства, чей адрес выставлен (порт ввода/вывода, память и т.д.). Собственно PCI поддерживает 64 разряда адреса для портов ввода/вывода, но в PC на процессорах архитектуры от Intel такое адресное пространство не поддерживается (не позволяет сам процессор).
Летом 1999 года консорциум SIG по PCI принял спецификацию принципиально нового варианта шины PCI - PCI-X. Несмотря на превосходные технические параметры, новая шина разрабатывалась под скептическим взглядом Intel, которая активно ведет разработку собственной шины NGIO. До настоящего времени практически все интерфейсы, разрабатываемые Intel (AGP,PCI, USB) принимались компьютерной индустрией Официальный взгляд Intel на PCI-X выглядит так: PCI-X хорошая шина, но жизнь ее будет недолговечной, так как когда мы разработаем и утвердим NGIO, PCI-X уйдет с рынка, проиграв NGIO по переспективности и производительности. Время покажет, кто победит, но очевидно, что только при поддержке PCI-X Intel в своих chipset она может найти широкое распространение.
Активное участие таких крупных компаний как IBM, Compaq, Hewlett-Packard в разработке PCI-X тем не менее дает новой шине существенные шансы на успех, и, кроме этого, в ее пользу говорит принятие спецификации PCI-X в то время как NGIO еще находится в разработке.
Основные отличия PCI-X от PCI:
· тактовая частота шины до 133 MHz
· возможно использование различных слотов для разных скоростей обмена данными; стандарт предусматривает 1 слот с частотой 133 MHz, 2 слота на 100 MHz, остальные слоты могут использоваться на частоты 33 и 66 MHz.
· значительно уменьшено время, выделяемое на операции в PCI-X (все времена в наносекундах).
| Параметр | 133 MHz PCI-X | 100 MHz PCI-X | 66 MHz PCI-X | 66 MHz обычная PCI | 33 MHz обычная PCI |
| Tval (max) | 3.8 | 3.8 | 3.8 | 6 | 11 |
| Tprop | 2.0 | 4.5 | 9.5 | 5 | 10 |
| Tskew | 0.5 | 0.5 | 0.5 | 1 | 2 |
| Tsu | 1.2 | 1.2 | 1.2 | 3 | 7 |
| Tcyc | 7.5 | 10 | 15 | 15 | 30 |
| Thold | 0 | 0 | 0 | 1 | 2 |
Основные функциональные отличия сведены в таблицу:
| Возможности | PCI | AGP1.0 | AGP2.0 | PCI-X |
| Совместимость с PCI | Да | Нет | Нет | Да |
| Скорость шины 100 Mhz | Нет | Нет | Нет | Да |
| Скорость шины 133 Mhz | Нет | 66 DDR | 66 DDR | Да |
| Скорость шины 266 Mhz | Нет | Нет | 66 QDR | Нет |
| Разрядность шины данных | 32/64 | 32 | 32 | 64 |
| Разрядность шины адреса | 32/64 | 32/36/64 | 32/47/64 | 64 |
| Максимальная скорость обмена, MBytes/s | 533 | 533 | 1064 | 1064 |
| Допустимость нескольких слотов | Да | Нет | Нет | Да |
| Иерархическая топология | Да | Нет | Нет | Да |
| Некогерентные транзакции | Нет | Да | Да | Да |
| Идентификатор устройства и шины (позволяет оптимизировать параметры обмена) | Нет | Нет | Нет | Да |
Примечания:
DDR - Double Data Rate - удвоенная скорость обмена данными
QDR - Quad Data Rate - учетверенная скорость обмена данными
Шина Compact PCI (cPCI) разрабатывалась на основе спецификации PCI версии 2.1. От обычной PCI эта шина отличается большим количеством поддерживаемых слотов для одной шины: 8 против 4. Всвязи с этим появились новые 4 пары сигналов запросов и предоставления управления шиной. Шина поддерживает 32-битные и 64-битные обмены (с индивидуальным разрешением байт). При частоте шины 33 МГц максимальная пропускная способность составляет 133 Мб/с для 32 бит и 266 Мб/с для 64 бит (в середине пакетного цикла). Возможна работа и на частоте 66 МГц, при этом производительность удваивается. Шина поддерживает спецификацию PnP - в ней работают все механизмы идентификации и автоконфигурирования, имеющиеся в PCI. Кроме того, в шине возможно применение географической адресации, при которой адрес модуля (на который он отзывается при программном обращении) определяется его положением в каркасе.
Для этого на коннекторе J1 имеются контакты GA0...GA4, коммутацией которых на "землю" для каждого слота может быть задан его двоичный адрес. Географическая адресация позволяет переставлять однотипные модули, не заботясь о конфигурировании их адресов (хорошая альтернатива системе PnP - здесь модуль "встанет" всегда в одни и те же адреса, которые без физического вмешательства ничем не собъются). Конструктивно платы Compact PCI представляют собой еврокарты высотой 3U (100 x 160 мм) с одним коннектором или 6U (233 x 160 мм) с двумя коннекторами. Коннекторы - 7-рядные штырьковые разъемы с шагом 2 мм между контактами, на кросс-плате - вилка, на модулях - розетки. Контакты коннекторов имеют разную длину: более длинные контакты цепей питания при установке модуля соединяются раньше, а при вынимании разъединяются позже, чем сигнальные.
Такое решение закладывает основу для реализации возможности "горячей" замены модулей. Собственно шина использует только один коннектор (J1), причем в 32-битном варианте не полностью - часть контактов выделяются на использование по усмотрению пользователя. 64-битная шина использует коннектор полностью. Одно посадочное место на кросс-плате резервируется под контроллер шины, на который возлагаются функции арбитража и синхронизации. На его коннекторе шиной используется большее число контактов, чем на остальных. У больших плат коннектор J2 отдается на использование по усмотрению пользователя (разработчика), а между коннекторами J1 и J2 может устанавливаться 95-контактный коннектор J3. Конструкция коннекторов позволяет для J2 применять специфические модификации, в которых может, например, присутствовать разделяющий экран и механические ключи. В шине предусматривается наличие независимых источников питания +5 В, +3.3 В и +/-12 В.
Разработка шины PCI (Peripheral Component Interconnect - соединение внешних компонент) началась весной 1991 года как внутренний проект корпорации Intel, а точнее организованная ею группа Special Interest Group. Появившаяся в июне 1992 году шина PCI (Release 0.1) как следующее поколение шин, не сохранившая совместимость с прежними шинами, имела несколько особенностей, позволивших ей за короткое время занять господствующее положение в ПК, оттеснив многочисленных конкурентов. Главными из них были ее открытая, доступная всем и каждому, архитектура и независимость от процессорной шины.
Special Interest Group занималась разработкой PCI для использования в системах с процессорами типа Pentium. Специалисты поставили перед собой цель - разработать недорогое решение, которое бы позволило полностью реализовать возможности нового поколения процессоров 486/Pentium/P6. Разработка проводилась "с нуля", а не была попыткой установки новых "заплат" на существующие решения. В результате работы уже в мае 1993 года появилась модернизированный вариант - версия PCI 2.0, которая стала стандартом де-факто среди компьютерных шин общего назначения. По сути дела эта шина не является локальной, т.к. она не подключена к системной шине напрямую, а для подключения использует Host Bridge (главный мост), а так же еще и Peer-to-Peer Bridge (одноранговый мост), который предназначен для соединения двух шин PCI. Кроме всего прочего, PCI является сама по себе мостом между ISA и шиной процессора.
Появление шины PCI на рынке стало своеобразной маленькой революцией. Разнообразие плат расширения, использующих шину PCI столь велико, что нет смысла их перечислять. Стандартом PCI предусмотрены три типа плат в зависимости от питания:
5В – для стационарных компьютеров;
3,3В – для портативных компьютеров;
универсальные платы могущие работать в обоих типах компьютеров.
являлась отдельной шиной, изолированной от процессора, однако она сохранила доступ к основной памяти;
являлась процессорно-независимой, т.к. разработчики Intel, в отличие от VLB, отказались от использования шины процессора, и работает с процессором через специализированный контроллер, т.н. "антресольную" (mezzanine) шину.
лагодаря такому решению, шина могла работать параллельно с шиной процессора, не обращаясь к ней за запросами. Например, процессор работает с кэшем или системной памятью, а в это время по сети на винчестер пишется информация. На самом деле так не получается, но загрузка шины процессора снижается значительно. Кроме того, стандарт шины был объявлен открытым и передан PCI Special Interest Group, которая продолжила работу по совершенствованию шины (в настоящее время доступен R2.1).
В шине PCI любая передача сигналов происходит пакетным образом, где каждый пакет разбит на фазы. Начинается пакет с фазы адреса, за которой, как правило, следует один или несколько фаз данных. Количество фаз данных в пакете может быть неопределенно, но ограничено таймером, который определяет максимальное время, в течение которого устройство может использоваться шиной. Такой вот таймер имеет каждое подключенное устройство, а его значение может быть задано при конфигурировании. Для организации работы по передачи данных используется арбитр. Дело в том, что на шине могут находиться два типа устройств – мастер (инициатор, хозяин, ведущий) шины и подчиненный. Мастер берет на себя контроль за шиной и инициирует передачу данных к адресату, т. е. подчиненному устройству. Мастером или подчиненным может быть любое подключенное к шине устройство и иерархия эта постоянно меняется в зависимости от того, какое устройство запросило у арбитра шины разрешения на передачу данных и кому. За бесконфликтную работу шины PCI отвечает чипсет, а точнее North Bridge. Но на PCI жизнь не остановила своего течения. Постоянное усовершенствование видеокарт привело к тому, что физических параметров шины PCI стало не хватать, что и привело к появлению AGP.
Шина PCI является синхронной 32-разрядной (кроме этого, существуют ее 64-разрядные версии, которые рассматриваться не будут, так как из-за своей высокой стоимости они используются исключительно в дорогих рабочих станциях и серверах). Шина получила возможность асинхронной работы от процессора с номинальными частотами 25 МГц, 30 МГц и 33 МГц, обеспечивая пропускную способность (с использованием пакетного режима пересылки данных) 133 Мб/с. По мере роста скоростей процессора частота шины PCI могла оставаться постоянной и составлять какую-то долю от шины FSB. Шина поддерживала удвоенное число слотов и/или периферийных устройств по сравнению с VLB - пять или больше, без всяких ограничений частоты или буферизации.
Другие функции облегчали использование PCI. Технология Plug and Play позволяла производитель автоматическую конфигурацию периферии без настройки IRQ, DMA и адресов ввода/вывода через перемычки. К тому же шина поддерживала разделяемые между несколькими устройствами IRQ, а также и свою собственную систему прерываний (она скрывается за обозначениями #A, #B, #C и #D).
Процессор через мосты (PCI Bridge) может быть подключен к нескольким каналам PCI, обеспечивая возможность одновременной передачи данных между независимыми каналами PCI. Важной особенностью шины является реализация принципа bus-master, что позволяет картам расширения производить обмен данными с памятью без обращения к процессору. Управление шиной-PCI bus mastering позволяло устройствами на шине получать контроль над ней и производить прямые передачи информации без участия процессора. В результате снижались задержки и нагрузка на процессор.
Для уменьшения количества проводников в шине PCI используется принцип мультиплексирования данных, то есть адрес и данные передаются по одним и тем же физическим линиям поочередно. PCI-устройства оборудованы таймером, определяющим максимальный период времени, когда устройство может занимать шину.
Автоконфигурирование устройств PCI (выбор запросов прерывания, каналов DMA) поддерживается средствами BIOS материнской платы в соответствие со стандартом Plug&Play. Действующая в настоящее время спецификация PCI 2.2 обеспечивает поддержку плат расширения с напряжениями питания как 3,3, так и 5В, причем тип платы определяется расположением ключей в разъеме. Если у карты PCI есть две ключевые выемки, то она поддерживает любой из вариантов слота, если же на ней только одна выемка ближе к передней части платы, то эта карта только на 3,3В. При расположении выемки ближе к задней части - карта 5В.
Основные возможности шины:
синхронный 32-х или 64-х разрядный обмен данными (64-разрядная шина в настоящее время используется только в Alpha-системах и серверах на базе процессоров Intel Xeon, но, в принципе, за ней будущее). При этом для уменьшения числа контактов (и стоимости) используется мультиплексирование, то есть адрес и данные передаются по одним и тем же линиям;
поддержка 5 В и 3,3 В логики (имеется 2 варианта питающего напряжения – 5 и 3,3 В). Разъемы для 5 и 3,3 В плат различаются расположением ключей. В 3,3 В карту нельзя вставить в 5 В разъем (и наоборот). Существуют и универсальные платы, поддерживающие оба напряжения. Следует отметить, что частота 66 МГц поддерживается только 3,3 В логикой;
частота работы шины 33 МГц или 66 МГЦ (в версии 2.1) , причем последняя возможна только на 3,3 В и 2 варианта ширины шины данных/адреса – 32 бита и 64 бита. Такие частоты позволяют обеспечить широкий диапазон пропускных способностей (с использованием пакетного режима): 132 Мб/с при 32-bit/33МГц; 264 Мб/с при 32-bit/66МГц; 264 Мб/с при 64-bit/33МГц; 528 Мб/с при 64-bit/66МГц. При этом для работы шины на частоте 66 МГц необходимо, чтобы все периферийные устройства работали на этой частоте. Сегментов может быть несколько, они соединяются друг с другом посредством мостов (bridge). Сегменты могут объединяться в различные топологии (дерево, звезда и т.п.);
разъем похож на MCA/VLB, но чуть длиннее (124 контакта). 64-разрядный разъем имеет дополнительную 64-контактную секцию с собственным ключом. Все разъемы и карты к ним делятся на поддерживающие уровни сигналов 5 В; 3,3 В и универсальные; первые два типа должны соответствовать друг другу, универсальные карты ставятся в любой разъем. Существует также расширение MediaBus шины PCI, введенное фирмой ASUSTek для подключения звуковых карт - дополнительный разъем, находящийся за PCI слотом, содержит сигналы шины ISA;
полная поддержка multiply bus master (например, несколько контроллеров жестких дисков могут одновременно работать на шине);
поддержка write-back и write-through кэша;
автоматическое конфигурирование карт расширения при подаче питания;
спецификация шины позволяет комбинировать до восьми функций на одной карте (например, видео + звук и т.д.);
шина позволяет устанавливать до 4 слотов расширения, однако возможно использование моста PCI-PCI для увеличения количества карт расширения;
PCI-устройства оборудованы таймером, который используется для определения максимального промежутка времени, в течении которого устройство может занимать шину.
При разработке шины в ее архитектуру были заложены передовые технические решения, позволяющие повысить пропускную способность. Шина поддерживает метод передачи данных, называемый "linear burst" (метод линейных пакетов). Этот метод предполагает, что пакет информации считывается (или записывается) "одним куском", то есть адрес автоматически увеличивается для следующего байта. Естественным образом при этом увеличивается скорость передачи собственно данных за счет уменьшения числа передаваемых адресов. 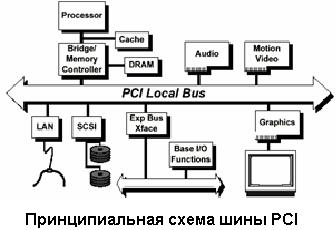
Шина PCI является той базой, на которой создана архитектура Microsoft/Intel Plug and Play PC architecture. Спецификация шины PCI определяет три типа ресурсов: два обычных (диапазон памяти и диапазон ввода/вывода, как их называет компания Microsoft) и configuration space - "конфигурационное пространство".
Согласно стандарту, выводы шины PCI делятся на обязательные (Required) и необязательные (Optional).Обязательные выводы должны присутствовать в любом PCI разъеме и карте.
Карты по стандарту PCI (Peripheral Component Interconnect), как и карты стандарта ISA также имеют снизу два небольших выступа. Основные отличия карт PCL от 16-разрядныхкарт ISA:
| ^ Назначение выводов слота PCI |
|||||
| Номер | Сигнал (сторона пайки) | Сигнал (сторона монтажа) | Номер | Сигнал (сторона пайки) | Сигнал (сторона монтажа) |
| 1 | TRST# | -12V | 48 | GND | AD10 |
| 2 | +12V | TCK | 49 | AD09 | GND |
| 3 | TMS | GND | 50 | GND/5V | GND/5V |
| 4 | TDI | TDO | 51 | GND/5V | GND/5V |
| 5 | +5V | +5V | 52 | C/BE0 | AD08 |
| 6 | INTA# | +5V | 53 | +3,3V | AD07 |
| 7 | INTC# | INTB# | 54 | AD06 | +3,3V |
| 8 | +5V | INTD# | 55 | AD04 | AD05 |
| 9 | Reserved | PRSNT1# | 56 | GND | AD03 |
| 10 | +5V | Reserved | 57 | AD02 | GND |
| 11 | Reserved | PRSNT2 | 58 | AD00 | AD01 |
| 12 | GND/3,3V | GND/3,3V | 59 | +5V | +5V |
| 13 | GND/3,3V | GND/3,3V | 60 | REQ64# | ACK64# |
| 14 | Reserved | Reserved | 61 | +5V | +5V |
| 15 | RST# | GND | 62 | +5V | +5V |
| 16 | +5V | CLK | 63 | GND | Reserved |
| 17 | GNT# | GND | 64 | C/BE7# | GND |
| 18 | GND | REQ# | 65 | C/BE5# | C/BE6# |
| 19 | Reserved | +5V | 66 | +5V | C/BE4# |
| 20 | AD30 | AD31 | 67 | PAR64 | GND |
| 21 | +3,3V | AD29 | 68 | AD62 | A63 |
| 22 | AD28 | GND | 69 | GND | A61 |
| 23 | AD26 | AD27 | 70 | AD60 | +5V |
| 24 | GND | AD25 | 71 | AD58 | AD59 |
| 25 | AD24 | +3,3V | 72 | GND | AD57 |
| 26 | IDSEL | C/BE3# | 73 | AD56 | GND |
| 27 | +3,3V | AD23 | 74 | AD54 | AD55 |
| 28 | AD22 | GND | 75 | +5V | AD53 |
| 29 | AD20 | AD21 | 76 | AD52 | GND |
| 30 | GND | AD19 | 77 | AD50 | AD51 |
| 31 | AD18 | +3,3V | 78 | GND | AD49 |
| 32 | AD16 | AD17 | 79 | AD48 | GND |
| 33 | 3,3V | C/BE2#80 | 80 | AD46 | AD47 |
| 34 | FRAME# | GND | 81 | GND | AD45 |
| 35 | GND | IRDY# | 82 | AD44 | GND |
| 36 | TRDY# | 3,3V | 83 | AD42 | AD43 |
| 37 | GND | DEVSEL# | 84 | +5V | AD41 |
| 38 | STOP# | GND | 85 | AD40 | GND |
| 39 | +3,3V | LOCK# | 86 | AD38 | AD39 |
| 40 | SDONE | PERR# | 87 | GND | AD37 |
| 41 | SBO# | +3,3V | 88 | AD36 | +5V |
| 42 | GND | SERR# | 89 | AD34 | AD35 |
| 43 | PAR | +3,3V | 90 | GND | AD33 |
| 44 | AD15 | C/BE1 | 91 | AD32 | GND |
| 45 | +3,3V | AD14 | 92 | Reserved | Reserved |
| 46 | AD13 | GND | 93 | GND | Reserved |
| 47 | AD11 | AD12 | 94 | Reserved | GND |
В настоящее время большинство карт являются картами PCI.
Введение шины вместе с процессором Pentium, усиленное очевидными преимуществами над конкурентами, позволило PCI выиграть войну шин и стать доминирующим стандартом в 1994 году. С тех пор практически все периферийные устройства, от контроллеров жёстких дисков и звуковых карт до видеокарт и сетевых плат, базировались на шине PCI.
С распространением массивов RAID, гигабитного Ethernet и других устройств с высокой пропускной способностью на системах потребительского класса, пропускной способности PCI в 133 Мбайт/с стало не хватать.
Производители чипсетов предвидели эти ограничения и вносили в свою продукцию различные изменения, чтобы снять часть нагрузки с шины PCI.
До 1997 года графическая подсистема наиболее сильно нагружала шину PCI. Выпуск вместе с чипсетом Intel 440LX ускоренного графического порта AGP (Accelerated Graphics Port) послужил двум целям: увеличить графическую производительность и убрать графические данные с шины PCI. Поскольку графическая информация стала передаваться по другой "шине" (по сути, порт AGP нельзя назвать шиной, поскольку он поддерживает только одно устройство), перегруженная шина PCI смогла освободиться для работы с другими устройствами.
Однако AGP явился лишь первым шагом в деле уменьшения нагрузки шины PCI. После этого производителям чипсетов пришлось переделать связь между северным и южным мостом. Старые чипсеты, типа линейки Intel 440, использовали шину PCI для связи между мостами. Шине PCI приходилось не только передавать информацию между мостами, но и обслуживать другие устройства PCI, в том числе IDE, Super I/O (параллельный и последовательный порты, PS/2), а также USB. Чтобы исправить ситуацию, Intel VIA и SiS стали использовать для связи северного и южного мостов специальную высокоскоростную линию, а затем перенесли IDE, Super I/O и USB на собственные выделенные линии к южному мосту.
Наконец, в апреле Intel анонсировала архитектуру CSA, поддерживаемую северным мостом чипсетов i875/i865, убрав гигабитный Ethernet с шины PCI.
Если AGP, CSA, Intel Hub Link, VIA V-Link и SiS MuTIOL можно назвать относительно успешными решениями в деле снятия нагрузки с шины PCI, они являются лишь промежуточными вехами.
Компания Samsung Electronics заявила, что она готовится выпустить аккумулятор для мобильных устройств на базе графена, который обладает большей емкостью, чем нынешние решения, и заряжается в несколько раз быстрее.
Специалисты Института передовых технологий Samsung (Samsung Advanced Institute of Technology) утверждают, что емкость нового графенового аккумулятора была повышена на 45%.
При этом новый аккумулятор заряжается всего за 12 минут, тогда как самым современным литий-полимерным аккумуляторами требуется около часа для полной зарядки.
Так как новый аккумулятор сохраняет свои свойства при температуре до 60 °С, его вполне можно будет использовать в автомобильной индустрии для оснащения электромобилей.
Институт передовых технологий Samsung уже запатентовал новую разработку в соответствующих ведомствах США и Южной Кореи.
Intel прекращает выпуск процессоров Broadwell-E
Линийка процессоров Broadwell-E представлена лишь четырьмя процессорами: Intel Core i7-6800K, 6850K, 6900K и 6950X.
Согласно сообщению об изменении продуктов, Intel продолжит принимать заказы на эти процессоры до 25 мая 2018 года.
Последняя поставка этих процессоров запланирована на 9 ноября того же года.
Так что если у вас есть планы по покупке именно этого HEDT решения, то у вас для этого ещё предостаточно времени.
Хотя, особого смысла в этой покупке нет, ведь на рынке есть куда более интересные предложения.
Процессоры Broadwell-E были представлены в 2016 году.
Реакция на их появления была смешанной, и уже через год им нашлась замена в виде Skylake-X.
Скорее всего, к концу следующего года Intel будет активно избавляться от этих CPU, возможно, даже снижая цену.
Память Z-NAND от Samsung конкурент Intel Optane
Сейчас самое быстрое решение в области накопителей, на базе памяти типа 3D XPoint, подготовлено Intel и Micron.
Однако Samsung не осталась в стороне и решила начать гонку сверхбыстрых накопителей.
Конкурировать корейская компания будет с памятью Z-NAND, которая представляет собой новую реализацию SLC (Single-Level Cell) NAND с улучшенным контроллером и другими усовершенствованиями, что позволит достичь большей производительности, как в последовательном, так и случайном режимах доступа.
Память SLC широко использовалась в SSD накопителях, однако последние годы в погоне за удешевлением и увеличением плотности стала использоваться память MLC и TLC.
Память Z-NAND возвращает индустрию к корням SLC.
Сейчас память 3D XPoint обеспечивает задержки на уровне 10/10 мкс, в то время как Z-NAND сможет предложить задержки 12-20/16 мкс.
По сравнению с Intel Optane P4800X объёмом 750 ГБ, готовящийся накопитель Samsung SZ985 объёмом 800 ГБ обеспечивает большую производительность при случайном чтении (550 000 IOPS против 750 000 IOPS), но проигрывает в записи (550 000 IOPS против 175 000 IOPS).
В плане скорости чтения/записи преимущество будет на стороне Z-NAND: 3,2/3,2 ГБ/с против 2,4/2,0 ГБ/с у Optane P4800X.
Надёжность же у обоих решений будет сравнимой.
Из-за ошибки основная система защиты Windows 10 уязвима к атакам
Когда операционная система Windows 10 ещё только готовилась к релизу, компания Microsoft, призывая пользователей отказаться от Windows 7, делала упор на то, что новый продукт стоит использовать прежде всего из-за сильной системы защиты ForceASLR, направленного на атаки, которые взаимодействуют со структурами данных.
Сама система защиты ForceASLR использует технологию рандомизации размещения адресного пространства (ASLR), которая заключается в том, что задаёт случайное размещение адресов структур данных.
Благодаря системе принудительного размещения адресных пространств, она распространяется не только на программы, которые разработаны с учётом поддержки этой технологии, как то было раньше, но для всех, даже если программы по умолчанию её не поддерживали.
Проблема в том, что данная система выполняет только половину от своих заявленных свойств.
С одной стороны, при первом запуске программы последней действительно присваивается случайный адрес в памяти.
Но при дальнейших запусках этот адрес уже не меняется, и в итоге отследить его становится значительно проще.
Сама возможность принудительно задать случайное размещения адресов для всех программ была введена ещё в Windows 8, и уже тогда появилась эта ошибка.
Как выяснилось теперь, на момент выпуска Windows 10, несмотря на все заверения и гарантии разработчиков, её так и не исправили.
Что ещё забавнее, если использовать ту же технологию, включив её через набор средств Microsoft EMET, в рамках операционной системы Windows 7, всё работает именно так, как планировалось изначально: адреса для программ присваиваются случайно при каждом перезапуске ПК, в то время как в более поздних системах таких результатов достичь так и не удалось.
Прямого решения этой проблемы для Windows 10 на момент написания новости не существует, равно как и пока что нет комментариев от Microsoft касательно данного факта.



