Pci x e разъемы интерфейс. Технология PCI Express
(Документ)
n1.doc
Шина PCI ExpressКорпорация Intel взяла на себя роль неформального лидера в организации PCI-SIG (Special Group for Interesting PCI Interface) в период создания архитектуры интерфейса ввода-вывода третьего поколения (Third Generation Input/Output Interconnection, 3GIO), известного также под названием Arapahoe. В 2001 г. было утверждено название PCI Express, а в 2003 г. появилась официальная спецификация версии 1.0.
Причина появления последовательной шины расширения довольно проста: необходимо равномерно наращивать производительность всех компонентов компьютеров, однако не все существующие интерфейсы масштабируются одинаково эффективно. Для параллельных шин основной проблемой является невозможность радикального повышения рабочих частот. Последовательную шину гораздо проще запустить на повышенных тактовых частотах, что значительно поднимает производительность. Более того, масштабируемость последовательных шин относительно легко достигается как за счет повышения частоты работы, так и увеличением числа линий.
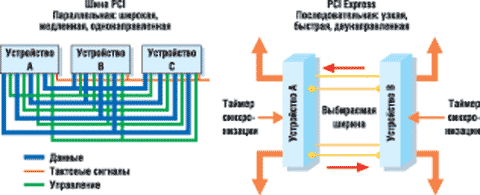
Первое и самое главное отличие новой шины: PCI Express является последовательной, а значит, четко разнесены уровни представления данных и уровень их передачи. Если в параллельной шине, например PCI, данные непосредственно появляются на шине (вместе с какой-то дополнительной информацией - CRC, адресом получателя и пр.), что и обуславливает простоту их посылки и получения, то в последовательной шине сказать что-либо о "физическом носителе" заранее невозможно. Информация, которую необходимо передать, просто упаковывается в пакеты, куда заносятся данные о получателе и коды обнаружения/исправления ошибок - а получившийся сплошной поток (где идут вперемешку данные, приложения и вспомогательная информация) уже передается - абсолютно неважно каким способом - через физическую среду.
Спецификация PCI Express предусматривает схему организации, аналогичную универсальной сетевой архитектуре ISO/SOI. На самом верхнем уровне располагаются прикладные программы, использующие PCI-устройство. Для них в архитектуре ничего не меняется: при обмене данными через шину PCI Express приложения просто обращаются к операционной системе. На уровне драйверов и конфигурирования архитектура PCI Express полностью совместима с интерфейсом PCI и потому является прозрачной для любой операционной системы, поддерживающей PCI. Тем самым обеспечена поддержка спецификаций ACPI и Plug-and-Play без какой-либо доработки общих программных компонентов.
Однако на других уровнях архитектуры произошли кардинальные изменения. Прежде всего, добавлено два новых уровня (Transaction Layer и Link Layer), функции которых аналогичны сетевым протоколам TCP/IP. Выполняемые функции абсолютно те же, что и у «сетевых» аналогов.
Transaction Layer получает запросы на чтение и запись от программного уровня и заведует первоначальной упаковкой данных, передачей их конкретному получателю и гарантиями корректной доставки сообщения. Если какой-то пакет не дойдет до получателя либо получатель обнаружит в принятом пакете ошибку, то протокол транспортного уровня будет повторять его передачу до тех пор, пока пакет не будет получен - тем самым гарантируется, что передаваемый через PCI Express поток данных достигнет получателя в целостности и сохранности. Каждый пакет снабжен уникальным идентификатором. На этом уровне поддерживается 32-битная и расширенная 64-битная адресация памяти, а также четыре адресных пространства - новое «пространство сообщений» (Message Space) и три уже известных по шине PCI - память, пространство ввода/вывода и конфигурационное пространство. Пространство сообщений предназначено для упрощения формата передачи данных - замены сигналов боковой полосы (side-band) в спецификации PCI 2.2 и исключения «специальных циклов» старого формата (прерывания, запросы управления энергосбережением, сброс).
Link Layer - здесь указывается уникальный номер пакета (его маршрутизация осуществляется по заголовку, относящемуся к транспортному уровню), по которому контроллеры шины принимают решение о направлении пакета в конкретную физическую линию передачи данных, здесь же располагается код обнаружения и исправления ошибок в принятом пакете (CRC), номер пакета, позволяющий отличить один пакет от другого, и разная вспомогательная информация (например, удостоверяющая, что пакет не был искажен в ходе его передачи). Однако в отличие от TCP/IP, маршрутизация пакетов (принятие решений о том, на которую шину перенаправить пакет, какой из нескольких претендующих пакетов передать первым) осуществляется на транспортном уровне. Интересно также, что пакет передается только в том случае, когда поступил сигнал готовности от буфера приема. Как следствие, уменьшается число повторов пакета и шина используется более эффективно.
Формат пакетов шины PCI-Express
Frame - начальный и конечный фрейм пакета - его добавляет физический уровень для определения начала и окончания передачи пакета данных;
Packet # - номер пакета, добавляется на сетевом уровне чтобы пакеты можно было отличить друг от друга;
Header - заголовок пакета, описывает тип пакета, получателя, приоритет и другие свойства, это информация транспортного уровня;
Data - собственно данные пакеты;
CRC - контрольная сумма пакета.
Fmt - указание типа заголовка (12 или 16 байт) и признак наличия в пакете данных;
Type - тип пакета (один из четырех основных типов - Memory, I/O, Config, Message и бит, определяющий запрос это или ответ на запрос);
RequestorID - получатель пакета (шина, устройство, функция устройства);
Traffic Class - используется для маршрутизации;
Address/Routing - адрес в памяти, куда предназначается пакет (32- или 64-разрядный) или иная информация о маршрутизации пакета;
Length - объем передаваемых в пакете данных;
Attr - вспомогательные атрибуты пакета (Snoop, Ordering);
Tag - идентификатор транзакции (Transaction Tag);
Reserved - зарезервированное поле;
Byte Enables - вспомогательная информация.
В самом низу этой пирамиды размещается собственно физическая реализация шины передачи данных - это две независимые дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием данных, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме «8/10» с исправлением ошибок. Избыточное кодирование позволяет исправлять многие простые ошибки, неизбежные на столь высоких частотах, без привлечения протоколов вышележащих уровней и без лишних повторных передач пакетов. Кроме того, это нужно для того, чтобы уменьшить долю «постоянных» составляющих в сигнале (не более 4 нулей или единиц подряд) - обеспечить баланс дифференциальной пары по постоянному току и позволить приемнику уверенно синхронизироваться по фронтам поступающего сигнала, поскольку никакого дополнительного («внешнего») синхронизирующего сигнала от тактового генератора в PCI Express не используется.
В качестве рабочих напряжений выбраны уровни от 0,2 до 0,4 вольт для логического нуля и от 0,4 до 0,8 вольт для логической единицы. Столь низкие напряжения выбраны из расчета удобства проектирования устройств для шины PCI-Express на современных 180-, 130- и 90-нм чипах, а также с целью снижения электромагнитных наводок и потребляемой мощности.
![]()
Технология PCI Express является открытым стандартом и разработана с расчетом на разнообразные применения - от полной замены шин PCI и PCI-X внутри настольных и серверных компьютеров, до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. При этом теоретическая пиковая производительность шины (на один канал передачи данных) примерно вдвое больше, нежели производительность «обычной» 33-мегагерцовой PCI - 250 против 133 Мбайт/с (или 200 против 100 Мбайт/с для реальной эффективной полосы пропускания данных). То есть для перехода на последовательную шину с сопоставимой производительностью понадобилось 75-кратное увеличение тактовой частоты.
Шина PCI Express помимо низкой латентности обладает очень высокой скоростью передачи данных в расчете на один сигнальный контакт - около 100 Мбайт/с. Для сравнения: у обычной шины PCI этот показатель - всего лишь 1,58 Мбайт/с на контакт (32 бит х 33 МГц / 84 сигнальных контакта), у 133-мегагерцовой PCI-X 1.0 - 11,4 Мбайт/с на контакт (64х133/93), у AGP 8X - 19,75 Мбайт/с на контакт (32х533/108), а у Intel Hub Link 2 - 26,6 Мбайт/с на контакт (2x16 бит на 8х66 МГц/40 контактов). Это позволяет, во-первых, экономить за счет контактов (на корпусах микросхем и позолоченных разъемах), а во-вторых - за счет более компактной разводки шин. Электрические улучшения (пониженное затухание в линиях передачи и повышенная чувствительность приемников данных) позволяют снизить требования к импедансу входных цепей и увеличить длину проводников шины на платах: сейчас она ограничивается 30,5 см для системных плат (от чипа до разъема), 9 см для плат контроллеров (и видеокарт) и 38 см для соединений между чипами на одной плате. Причем разводка может быть как четырех-, так и шестислойной - без каких-то особо критичных требований.
Как и в любой сети, передаваемые данные дополнительно нарезаются небольшими кусочками - фреймами. При тактовая частоте шины 2,5 ГГц без учета кодирования мы получим скорость передачи в 2,5 Гбит/с в каждом направлении. С учетом выбранной схемы «8/10» получается 250 Мбайт/с, однако многоуровневая сетевая иерархия не может не сказаться на скорости работы и реальная производительность шины оказывается значительно ниже - всего лишь чуть более 200 Мбайт/с в каждую сторону (в пике до 220–230 согласно документации Intel). Впрочем, даже это на 50% больше, чем теоретическая пропускная способность шины PCI. Но это далеко не предел: пожалуй, единственная интересная особенность PCI Express - возможность объединения в одну шину нескольких независимых линий передачи данных. Стандартом предусмотрено использование 1, 2, 4, 8, 16 и 32 линий - передаваемые данные поровну распределяются по ним по схеме «первый байт на первую линию, второй - на вторую, …, n-й байт на n-ю линию, n+1-й снова на первую, n+2 снова на вторую» и так далее.
Это не параллельная передача данных и даже не увеличение разрядности шины (поскольку все передающиеся по линиям данные передаются абсолютно независимо и асинхронно) - это именно объединение нескольких независимых линий. Причем, передача по нескольким линиям никак не влияет на работу остальных слоев «пирамиды» и реализуется сугубо на «нижнем», физическом уровне. Именно этим достигается великолепная масштабируемость шины PCI Express - она позволяет организовывать шины с максимальной пропускной способностью до 32x200=6,4 Гбайт/с.


PCI Express относится к шинам класса «точка-точка», то есть одна шина может соединять только два устройства (в отличие от PCI, где на общую шину «вешались» все PCI-слоты компьютера), поэтому для организации подключения более чем одного устройства в топологию организуемой PCI Express, как и в Ethernet-решениях на базе витой пары или устройствах USB, придется вставлять «хабы» и «свитчи», распределяющие поступающий сигнал по нескольким шинам. Это тоже одно из главных отличий PCI Express от прежних параллельных шин.
Дополнительные возможности PCI Express
Стоит упомянуть и о других новых возможностях, появившихся в стандарте PCI Express (по сравнению с PCI) - поддержке виртуальных каналов, QoS (Quality of Service) и изохронной передаче данных. Начнём с рассмотрения механизма, обеспечивающего совместимость PCI Express с обычным PCI. Как мы уже заметили, сегодняшний физический уровень PCI Express обеспечивает лишь соединения «точка-точка», что вынуждает использовать для подключения множества устройств специальные свитчи, объединяя устройства в «звездную» сеть. Но «классическая» PCI - параллельная шина, к тому же использующая механизм прерываний, не поддерживаемый в PCI Express! Сравните: если в случае PCI у нас в ПК было, скажем, две шины - одна для графического адаптера (AGP), и другая - для всех остальных устройств, обращения к которым так и производились по адресу - «шина такая-то, устройство такое-то», то при переходе на PCI Express от былой топологии не остается и следа. В нашем примере (см. рисунок) появляется семь шин PCI Express (не считая шины, соединяющей северный и южный мосты чипсета), причем шесть из них относятся к единственной бывшей PCI (bus 1). К счастью, механизмы маршрутизации, заложенные в стандарт, позволяют особенно не задумываться над этим вопросом - при пересылке пакетов «свитчи» сами определят, на какую шину его необходимо передать. Отправителю достаточно указать устройство-получатель и пакет каким-то образом до него дойдет. То есть ПО теперь работает не непосредственно с аппаратурой, а с непонятно каким образом функционирующими виртуальными каналами данных (старая схема адресации «шина-устройство-функция устройства» при этом сохраняется, хотя такое разделение теперь достаточно условно). Для полной имитации «обычной» PCI-шины контроллер PCI Express даже имитирует прерывания этой шины при поступлении от устройства соответствующего сообщения (служебная информация вроде вызова прерывания также передается в виде пакетов). Впрочем, как уже говорилось, к механизму сообщений есть и прямой доступ, без использования этого режима совместимости.
Итак, с устройствами можно продолжать работать, как с обычными PCI, но «виртуальность» этой шины позволяет обеспечить большую гибкость полученной системы. Каждый виртуальный канал до устройства (напомним, что их может быть по нескольку на каждое устройство - для этого и нужна последняя компонента PCI-адреса) никак не привязан к «физическому» носителю, а значит, его можно настроить произвольным образом. Например, стандарт позволяет указывать для виртуального канала его пропускную способность и максимально допустимую задержку передачи данных по нему. Физическая среда передачи данных, конечно, накладывает некоторые ограничения на допустимые здесь значения - больше 200 Мбайт/с через PCI Express 1x при всем желании пропустить невозможно. Виртуальные каналы создаются и изменяются «на лету» - например, плата видеозахвата может большую часть времени обходиться единственным каналом доставки сообщений и запрашивать дополнительный виртуальный канал для передачи данных лишь в момент подключения к ней внешнего устройства. Если у контроллера PCI Express для создания канала не хватит физических ресурсов, то он честно об этом сообщит, но если канал будет создан, то он будет в точности отвечать запрошенным параметрам и никакие «внешние» события - активизация других PCI-устройств, действия пользователя и т.п. на него не повлияют (QoS - запрошенный сервис обладает гарантированным качеством).
Помимо каналов с гарантированной пропускной способностью PCI Express поддерживает также создание изохронных каналов - информация по ним передается с гарантированной максимальной задержкой (это нужно для устройств, работающих в режиме реального времени - например, для устройств, передающих по сети человеческую речь). Впрочем, QoS устройство может отключить (собственно при работе в режиме совместимости с PCI так и происходит), тогда «виртуальным каналам» устройства будут отводиться все остающиеся после QoS-каналов ресурсы шины. «Физическая» реализация QoS и изохронности зависит от конкретной реализации контроллеров PCI Express и использующихся «свитчей», но в конечном итоге все это сводится лишь к тому, какие из пакетов, претендующих на одновременную передачу по одной и той же шине, контроллер пошлет в первую очередь, а какие - лишь по мере возможности. Возможный вариант: изохронные пакеты идут «вне очереди», остальное время пропорционально делится между устройствами, требующими некоторую заданную полосу пропускания и лишь все, что остается распределяется между «обычными», не приоритетными пакетами данных, которые передаются в порядке их поступления в контроллер.
В новой шине также поддерживаются режимы пониженного энергопотребления - в полном соответствии с «четырехуровневыми» стандартами ACPI. Линия PCI Express может «отключаться», если она не используется в данный момент для передачи данных - отключаются линии передачи тактового сигнала, линии приема и передачи данных (и вместе с ними могут отключаться и приемник и передатчик в PCI-Express контроллере), с устройства может быть снято питание - целиком (устройство «логически выключено») или частично (остается маломощное дежурное напряжение питания, функционирует «линия пробуждения» WAKE#, по которой передается сигнал на перевод устройства в нормальный рабочий режим). Если шина состоит из нескольких линий, то при небольшой загрузке шины можно отключать ненужные в данный момент линии (например, использовать PCI Express x4 как x1, а три линии выключить). Переключение в «энергосберегающий» режим при этом может потребовать как само устройство PCI Express, так и «система» в целом - скажем, при переходе в «спящий режим» (hibernate). В «десктопных» вариантах шины PCI Express энергосберегающие режимы являются необязательными (то есть могут быть реализованы, а могут и нет), но в мобильных описанные возможности являются обязательными.
Аппаратные конфигурации
В плане практической реализации шина PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный и южный мосты чипсета, коммутатор и конечные устройства. Новым термином здесь является коммутатор (switch). Он заменяет одну шину с множественными подключениями коммутируемой технологией

Коммутатор обеспечивает одноранговую связь между различными конечными устройствами, то есть предотвращает попадание излишнего трафика к мосту. PCI Express призвана обеспечить высокую пропускную способность на контакт с низким количеством служебной информации и низкими задержками. Поддерживаются несколько виртуальных каналов на один физический.
Примерные схемы включения PCI Express в различные типовые вычислительные системы выглядят следующим образом (на рисунках шины PCI Express показаны оранжевыми линиями).
В «десктопных» системах шина PCI-Express 16x в первую очередь вытесняет AGP 8x в качестве «графической шины», соединяющей видеокарту и северный мост чипсета. Во вторую очередь на PCI-Express пересадят многие интегрированные устройства - гигабитный сетевой контроллер, RAID-контроллер и прочие. К обычным PCI-слотам добавят пару PCI-Express x1. В качестве межчипсетной шины (соединяющей мосты чипсета) PCI Express выступает вместе со старыми шинами (Intel HubLink, VIA VLink, SiS MuTIOL) - производители чипсетов пока не желают отказываться от своих проприетарных шин.
Десктоп:

Сервер:

С серверными архитектурами все проще - там не предусматривается традиционной «двухмостовой» чипсетной схемы. На PCI-Express переведут интегрированные гигабитные сетевые контроллеры; традиционные периферийные шины (PCI-X, SATA, LPC) сохранятся, но к чипсету будут подключаться через специальные мосты на шину PCI Express. Аналогичная схема предусмотрена для сетевых решений - но в силу специфики периферии там новая шина вытеснит практически все остальные.
Как видно из этих рисунков, PCI Express предполагается использовать для связи всех ключевых компонентов системы, кроме «внешних» (USB 2.0) и накопителей на магнитных дисках (SATA как более подходящий для работы именно с HDD). Некоторое время слоты PCI и PCI-X продолжат свое существование (они будут подключаться через специальные мосты PCI-to-PCI Express), но почти все интегрированные контроллеры будут подключаться уже с использованием PCI Express. В том числе, PCI Express свяжет между собой северный и южный мосты чипсета. Поскольку реализация что шины AGP, что предназначающейся ей на смену PCI Express x16 требует весьма сложной разводки9, то слот AGP из будущих чипсетов исчезнет полностью. Впрочем, SiS, VIA и ALi/ULi на первых порах будут выпускать чипсеты с шиной AGP и PCI Express x1, но без PCI Express x16.
Шина ATA (IDE)
Интерфейс ATA (AT Attachment for Disk Drives) разработан в 1986 г. для подключения накопителей на жестких магнитных дисках в компьютерах IBM PC/AT с шиной ISA-Bus. Интерфейс появился в результате установки контроллера жесткого диска в сам накопитель, то есть создания устройства со встроенным контроллером - IDE (Integrated Device Electronic). Фактически контроллер жесткого диска был перенесен с материнской платы PC/AT на плату электроники накопителя. Поскольку стандартный контроллер жестких дисков AT позволял подключать до двух накопителей, эту возможность включили и в новый интерфейс. Оба накопителя подключили к одной интерфейсной шине, а для обеспечения программной совместимости бит выбора накопителя в регистре номера головки и номера устройства стали использовать для выбора устройства (фактически, для выбора контроллера). Для организации взаимодействия пары устройств на шине ввели несколько дополнительных сигналов.
Поскольку набор сигналов получился достаточно универсальным, он позволяет подключать любое устройство со встроенным контроллером, которому в пространстве портов ввода/вывода достаточно того же набора регистров и которое способно поддержать принятый режим выбора устройства. Принятая система команд и регистров, являющаяся частью спецификации ATА, ориентирована на блочный обмен данными с устройствами прямого доступа. Для иных устройств существует спецификация ATAPI, основанная на тех же аппаратных средствах.
В системе адресации данных интерфейса ATА изначально указывается адрес цилиндра (Cylinder), головки (Head) и сектора (Sector) - CHS. Позже стали различать физическую (реальную для накопителя) и логическую (по которой с устройством общается программа) адресацию CHS. При этом одно и то же устройство могло иметь разные варианты логической архитектуры. Взаимное преобразование логической и физической адресации выполняется встроенным контроллером устройства. В настоящее время используется линейная адресация логического блока LBA (Logical Block Addressing), где адрес блока (для дисков - сектора) определяется 28-битным числом.
Архитектурой интерфейса АТА предусмотрены следующие компоненты:
хост-адаптер для сопряжения интерфейса АТА с системной шиной;
шлейф с 40 или 80 проводниками, с двумя или тремя разъемами;
ведущее устройство (Master), официально именуемое Device 0;
ведомое устройство (Slave), официально именуемое Device 1.
Режим кабельной выборки включается перемычкой CS (Cable Select - кабельная выборка). В этом случае оба устройства на шине конфигурируются одинаково (в режим CS), а адрес устройства определяется его положением на шлейфе. Режим кабельной выборки работоспособен, если он поддерживается всеми устройствами данного канала шины, включая и хост-адаптер. Недостатком кабельной выборки является привязка физического положения устройств к кабелю: ведущее устройство должно быть ближе к адаптеру, чем ведомое устройство.
Более распространен режим явной адресации, когда адрес каждого устройства задается перемычками, состав которых у разных моделей варьируется. В принципе достаточно лишь указать устройству его роль (Master/Slave). Следует учитывать, что перестановка джамперов воспринимается устройством зачастую только по включении питания.
Оба устройства воспринимают команды от хост-адаптера одновременно. Однако исполнять команду будет лишь выбранное устройство, определяемое состоянием регистра выборки. Выходные сигналы на шину ATA имеет право выводить только выбранное устройство. Такая система подразумевает, что, начав операцию обмена с одним из устройств, хост-контроллер не может переключиться на обслуживание другого устройства той же шины ATА до завершения начатой операции обмена. Параллельно могут работать только устройства IDE, подключаемые к разным шинам (каналам) ATА.
| Режим | Минимальное время цикла, нс | Скорость передачи, Мбайт/с |
| РЮ mode 0 | 600 | 3,3 |
| РЮ mode 1 | 383 | 5,2 |
| РЮ mode 2 | 240 | 8,3 |
| РЮ mode 3 | 180 | 8,3 |
| РЮ mode 4 | 120 | 16,6 |
| РЮ mode 5 | 100 | 20 |
| Single word DMA Mode 0 | 960 | 2,08 |
| Single word DMA Mode 1 | 480 | 4,16 |
| Single word DMA Mode 2 | 240 | 8,33 |
| Multiword DMA Mode 0 | 480 | 4,12 |
| Multiword DMA Mode 1 | 150 | 13,3 |
| Multiword DMA Mode 2 | 120 | 16,6 |
| Multiword DMA Mode 3 | 100 | 20 |
| Multiword DMA Mode 4 | 80 | 33 |
| Multiword DMA Mode 5 | 60 | 66 |
| Multiword DMA Mode 6 | 40 | 100 |
| Multiword DMA Mode 7 | 20 | 133 |
Стандарт ATА имеет систему команд, рассчитанную на приводы магнитных дисков. Для операций, связанных с обменом данными, предназначены команды, использующие программные режимы PIO (Programmed Input/ Output) или блочные режимы DMA (Direct Memory Access). Блочный режим за счет сокращения числа прерываний, которые должен обслужить процессор, в многозадачной системе позволяет повысить производительность дискового обмена. Обмен по каналу DMA в отличие от PIO занимает только шины ввода/вывода и памяти. Процессору требуется выполнить только процедуру инициализации канала, после чего до прерывания от устройства, полученному в конце передачи блока, он свободен. Режимы обмена по каналу DMA могут быть одиночными и множественными. При множественном режиме (Multiword DMA) на сигнал запроса хост отвечает потоком циклов DMA. Если устройство не справляется с этим потоком, оно может приостановить поток, а по готовности к продолжению - возобновить. Множественный режим позволяет развивать более высокую скорость передачи. В режиме Ultra DMA за каждый такт передаются два слова данных, одно по фронту синхронизирующего сигнала, другое по спаду. Это позволяет повысить пропускную способность шины, не увеличивая максимальную частоту переключений сигналов.
На сегодняшний день последней спецификацией интерфейса считается ATА-133. Ее появление обусловлено тем, что спецификацией AT А-100 допускалось использование жестких дисков объемом до 137 Гбайт, что связано с 28-битной адресацией сектора. Однако современные диски быстро преодолели этот рубеж. В спецификации AT А-133 используется 48-битная адресация сектора, что позволяет адресовать диски объемом до 144 петабайт. Кроме того, внедрение режима Multiword DMA Mode 7 позволило увеличить скорость передачи до 133 Мбайт/с.
Спецификация ATAPI
Для подключения к интерфейсу ATА накопителей CD-ROM, стримеров и ряда других устройств набора регистров и системы команд АТА оказывается недостаточно. Для них существует аппаратно-программный интерфейс ATAPI (ATA Package Interface - пакетный интерфейс АТА). Устройство ATAPI поддерживает минимальный набор команд АТА, а также 16-байтный командный пакет, который пересылается хост-контроллером в регистр данных устройства. Структура командного пакета аналогична таковой для шины SCSI, что обеспечивает схожесть драйверов одних и тех же устройств, имеющих интерфейсы SCSI и ATAPI. Классификация устройств совпадает с принятой в SCSI, информация о классе устройства размещается им самостоятельно в начале блока параметров идентификации.
Интерфейс ATAPI можно использовать с любыми адаптерами АТА, поскольку для контроллера поддержка ATAPI иногда выполняется чисто программными средствами. Специфические команды вместе с необходимыми параметрами передаются по команде Packet, код которой является недействительным для устройств АТА.
Шина
Serial
ATA
Спецификации последовательного интерфейса Serial ATA (SATA) версии 1.0 были опубликованы в августе 2001 г., а спецификация Serial ATA II - в октябре 2002 г. В настоящее время интерфейс SATА считается основным для подключения накопителей различных типов в современных платформах настольных ПК.
Стандарт SATА подразумевает последовательную передачу данных, а потому сигнальные линии задействуют всего две дифференциальные пары. Одна из них работает на передачу, а другая - на прием. Всего же в кабеле SATA допускается использование семи проводников, три из которых предназначены для заземления. Максимальная длина кабеля при этом составляет один метр.
По сравнению с традиционным параллельным интерфейсом ATА шина Serial ATA имеет большую помехозащищенность и мало восприимчива к электромагнитным помехам благодаря использованию низкоуровневых дифференциальных сигналов. Уровень сигнала измеряется не по отношению к «земле», а по отношению к уровню сигнала в соседнем проводе, то есть как разница сигналов в двух проводниках. Любая наведенная помеха сказывается на обоих сигналах, однако их дифференциальная разница при этом не меняется.
На логическом уровне для передачи данных используется двухэтапное кодирование 8bit/10bit. При логическом кодировании 8/10 каждые 8 бит исходной последовательности данных замещаются 10-битным кодом в соответствии с определенными правилами. В результате для 256 возможных комбинаций из 8 бит на входе получают 1024 возможные комбинации для 10 бит на выходе. При классическом подходе разрешенными из этих 1024 комбинаций считаются только 256, а остальные - запрещенными. Такая избыточность используется для повышения помехоустойчивости кодирования.
Однако в протоколе SATА используется больше, чем 256 разрешенных комбинаций, за счет двухэтапного кодирования. При этом каждой входной последовательности может соответствовать несколько выходных, а какая именно выходная комбинация будет использована, зависит от контрольного сигнала rd, формируемого в процессе передачи.
При кодировании согласно протоколу SATА исходные 8 бит разбиваются на подгруппы длиной 5 бит и 3 бит. На первом этапе подгруппа 5 бит подвергается кодированию 5bit/6bit, то есть каждые 5 бит заменяются на 6 бит. На втором этапе оставшиеся 3 бита подвергаются кодированию 3bit/4bit. При кодировании каждой группы (сначала 5 бит, а потом оставшихся 3 бит) формируется специальный бинарный контрольный сигнал rd (Running Disparity), который может быть либо отрицательным (rd-), либо положительным (rd+). Кодирование 5bit/6bit для 32 возможных 5-битных комбинаций на входе обеспечивает 46 комбинаций по 6 бит на выходе. Получают эти 46 комбинаций следующим образом: каждой из 32 возможных 5-битных комбинаций на входе ставятся в соответствие две 6-битные выходные последовательности: прямая и инверсная, за исключением тех 6-битных последовательностей, в которых количество единиц совпадает с количеством нулей - отсюда именно 46 возможных комбинаций на выходе.
При кодировании 3bit/4bit для 8 возможных 3-битных комбинаций на входе существует 14 возможных 4-битных комбинаций на выходе. Здесь также прямая или инверсная выходная последовательность определяется текущим значением контрольного сигнала rd. Если сигнал rd положителен, то используется прямая последовательность, а если отрицателен - то инверсная. При этом текущее значение сигнала rd определяется по предыдущей переданной последовательности из 6 или 4 бит.
Правило для формирования сигнала rd достаточно простое. Сигнал положителен, если количество единиц больше количества нулей в группе закодированных бит. Исключение составляют последовательности с равным количество нулей и единиц. Например, для последовательностей 000111 (подгруппа 6 бит) и 0011 (подгруппа 4 бит) сигнал считается положительным, а для последовательностей 111000 и 1100 - отрицательным. Во всех остальных случаях сигнал rd нейтрален и не меняет своего состояния. Кроме логического двухэтапного кодирования, при передаче данных используется метод циклического избыточного контроля CRC-32 (Cyclic Redundancy Check). На физическом уровне используется код NRZ (Non Return to Zero).
Другой особенностью интерфейса SATА является организация взаимодействия между контроллером и диском по принципу «точка-точка». Напомним, что интерфейс АТА предусматривает подключение на один канал до двух устройств (Master и Slave); соответственно полоса пропускания 133 Мбайт/с разделяется между устройствами. В интерфейсе SATA к одному контроллеру можно подключить только один жесткий диск, поэтому каждому устройству стандарта SATА предоставляется вся полоса пропускания 150 Мбайт/с.
Спецификацией SATА предусмотрена поддержка технологии горячей замены дисков, то есть подключения и отключения устройств на работающей шине. Пока такая возможность не слишком актуальна для настольных платформ, но с развитием миниатюрных переносных жестких дисков она может быть востребована.
Развитием спецификации
SAT
А стал интерфейс
Serial
ATA
II
, который поддерживают современные версии южных мостов НМСЛ ведущих производителей, например компаний Intel, nVidia, VIA и SiS. Явным отличием спецификации SAT AII выглядит увеличение пропускной способности шины до 300 Мбайт/с. Однако спецификация имеет много внешне малозаметных улучшений, существенно влияющих на эффективность накопителей. Например, в спецификацию введены специальные мосты-умножители, позволяющие подключать до 15 устройств на один канал SATА. Но главные усовершенствования связаны с оптимизацией очереди команд.
Жесткий диск, в отличие от чисто электронных компонентов компьютера, представляет собой электронно-механическое устройство. Наличие электромеханической части, имеющей гигантское, по «электронным» меркам, время реакции, обусловливает неизбежные задержки в поиске и передаче данных. В спецификации SATA II приняты меры по уменьшению задержек за счет изменения порядка выполнения команд, поддержанные средствами организации очередей команд.
Наиболее известный алгоритм минимизации задержек поиска (перемещения головок) и вращения называется Rotational Position Ordering (упорядочение по вращению). Используя этот алгоритм, накопитель может расположить команды обращения к магнитным носителям так, чтобы сократить время доступа до минимума. Первоначально использовались алгоритмы, минимизирующие расстояние, на которое перемещается головка, сокращая тем самым время поиска. Но при этом общее время доступа могло увеличиваться, поскольку после быстрого перемещения головки на нужную дорожку приходилось ждать почти полного оборота пластины для появления под головкой требуемого сектора. Алгоритм Rotational Position Ordering при выстраивании очереди команд учитывает оба фактора - дистанцию поиска и текущее положение головок на окружности пластин. В результате команды выполняются в таком порядке, чтобы сократить до минимума общее время доступа, включающее обе задержки- поиска и вращения. Именно этот алгоритм был положен в основу технологии Native Command Queuing (NCQ).
Жесткие диски SATAII могут не только выстраивать принятые команды наиболее оптимальным с точки зрения механических перемещений образом, но и динамически добавлять поступившие в процессе обработки команды в нужные позиции очереди. Перестановка ожидающих выполнения команд производится с учетом не только положения головок после выполнения последней команды, но и множества других факторов. Для определения того, какая команда будет выполняться следующей, используются сложные алгоритмы, учитывающие переключение головок, времена поиска определенных дорожек, режимы работы (например, в режиме с пониженным уровнем шума последовательность может отличаться от обычного режима, поскольку здесь учитывается, что поиск должен создавать минимум шума). Принимаются во внимание такие параметры, как расстояние, на которое перемещаются головки, начальное положение и направление поиска, характеристики ускорения и замедления позиционера, различные времена установления головок на дорожке для чтения и записи, попадания и промахи в кэш-памяти при чтении, наличие кэширования записи и многие другие. Кроме того, применяются алгоритмы, предупреждающие «зависание» отдельных команд в очереди.
Другая составляющая технологии - уменьшение задержек вращения жесткого диска. Эффект достигается двумя методами. Первый - это перегруппировка ожидающих выполнения команд аналогично тому, как это делается для минимизации задержек поиска. Если накопитель выполняет команды в порядке их поступления, то в ситуации, когда сначала поступает команда чтения сектора А, затем В, а затем С, для выполнения всех трех команд потребуется примерно 1,5 оборота дисковых пластин. Изменив же порядок выполнения команд так, чтобы после А считывался сектор С и только потом В, можно «уложиться» менее чем в один оборот и сократить общее время выполнения запроса более чем на треть.
Второй способ - это так называемый измененный порядок доставки данных (out-of-order data delivery). Это значит, что головка не обязательно должна начинать чтение (запись) с первого LBA-сектора запрошенного блока данных. Она может начать передачу с любого наиболее «удобного» для нее сектора, входящего в запрошенный блок, а недостающее начало блока передать в конце текущего оборота диска. Использование измененного порядка доставки позволяет в наихудшем случае затратить на передачу блока данных не более одного оборота пластины. Без него в наихудшем случае время передачи составит один оборот плюс время передачи всех входящих в блок секторов.
Для реализации изменения порядка следования команд необходима маркировка каждой команды, отличающая ее от других команд в очереди. В NCQ для этого используется 5-битный тег, поэтому максимальное число команд в очереди не может превышать 32. Базой для реализации NCQ в рамках протокола Serial ATA стали три механизма: сообщения о статусе завершения команды без состязаний (race-free status return), агрегирования прерываний (interrupt aggregation) и прямого доступа к памяти по инициативе устройства (First Party DMA).
Механизм Race-Free Status Return позволяет устройству сообщать о статусе выполнения любой команды в любое время. Никаких специальных «переговоров» с хост-адаптером для посылки статусного сообщения не требуется. Накопитель может сообщать о завершении нескольких команд подряд или даже одновременно.
Механизм Interrupt Aggregation позволяет обрабатывать одно прерывание для нескольких команд. Обычный алгоритм общения накопителя с хост-адаптером предусматривает обработку прерывания каждый раз, когда завершается выполнение очередной команды. Чем больше прерываний, тем больше нагрузка на хост-адаптер и центральный процессор. При использовании NCQ среднее количество прерываний, генерируемых на одну команду, может быть меньше единицы. Если накопитель завершает несколько команд в течение короткого промежутка времени, отдельные прерывания могут объединяться (агрегироваться). Тогда хост-контроллеру достаточно обработать одно прерывание на несколько команд.
Механизм First Party DMA позволяет накопителю инициировать операцию прямого доступа к памяти для передачи данных без участия хост-контроллера и центрального процессора. Накопитель выбирает контекст ПДП, посылая хост-контроллеру так называемую DMA Setup FIS (Frame Information Structure, базовая единица обмена данными в протоколе Serial ATA). Эта FIS сообщает тег команды, для которой следует создать канал ПДП.
На основании значения тега хост-контроллер загружает в контроллер ПДП компьютера указатель на соответствующую этой команде PRD-таблицу (Physical Region Descriptor - структура, используемая для описания областей памяти, с которыми производится обмен данными), после чего передача данных происходит без вмешательства со стороны ЦП. Именно благодаря этому механизму накопитель может эффективно реорганизовывать команды, поскольку место в памяти для обмена данными он выбирает по собственной инициативе. Получив команду, накопитель должен знать, исполнять ли ему ее немедленно или ставить в очередь. Он также должен знать, какой протокол передачи данных будет использоваться - NCQ, DMA, РЮ и т. д. Эту информацию он получает, декодируя код операции команды.
В целом внедрение интерфейса Serial ATA позволило серьезно повысить эффективность подсистемы накопителей в настольных компьютерах и вывести ее на уровень, ранее характерный для профессиональных серверных решений. Например, использование RAID-массивов с дисками SATA заметно улучшает производительность мультимедийных приложений, игр и других программ, требующих обработки больших объемов информации.
PCI Express это шина, которая используется для подключения разнообразных комплектующих к настольному ПК. С ее помощью подключают видеокарты, сетевые карты, звуковые карты, SSD накопители, WiFi модули и другие подобные устройства. Разработку данной шины начала компания Intel в 2002 году. Сейчас разработку новых версий данной шины занимается некоммерческая организация PCI Special Interest Group.
На данный момент шина PCI Express полностью заменила такие устаревшие шины как AGP, PCI и PCI-X. Шина PCI Express размещается в нижней части материнской платы в горизонтальном положении.
В чем отличия PCI Express от PCI
PCI Express это шина, которая была разработана на основе шины PCI. Основные отличия между PCI Express и PCI лежат на физическом уровне. В то время как PCI использует общую шину, в PCI Express используется топология типа звезда. Каждое PCI Express устройство подключается к общему коммутатору отдельным соединением.
Программная модель PCI Express во многом повторяет модель PCI. Поэтому большинство существующих PCI контроллеров могут быть легко доработаны для использования шины PCI Express.

Слоты PCI Express и PCI на материнской плате
Кроме этого, шина PCI Express поддерживает такие новые возможности как:
- Горячее подключение устройств;
- Гарантированная скорость обмена данными;
- Управление потреблением энергии;
- Контроль целостности передаваемой информации;
Как работает шина PCI Express
Для подключения устройств шина PCI Express использует двунаправленное последовательное соединение. При этом такое соединение может иметь одну (x1) или несколько (x2, x4, x8, x12, x16 и x32) отдельных линий. Чем больше таких линий используется, тем большую скорость передачи данных может обеспечить шина PCI Express. В зависимости от количества поддерживаемых линий размер сорта на материнской плате будет отличаться. Существуют слоты с одной (x1), четырьмя (x4) и шестнадцатью (x16) линиями.

Наглядная демонстрация размеров слота PCI Express
При этом любое PCI Express устройство может работать в любом слоте, если слот имеет такое же или большее количество линий. Это позволяет установить PCI Express карту с разъемом x1 в слот x16 на материнской плате.
Пропускная способность PCI Express зависит от количества линий и версии шины.
|
В одну/обе стороны в Гбит/с |
|||||||
|
Количество линий |
|||||||
| PCIe 1.0 | 2/4 | 4/8 | 8/16 | 16/32 | 24/48 | 32/64 | 64/128 |
| PCIe 2.0 | 4/8 | 8/16 | 16/32 | 32/64 | 48/96 | 64/128 | 128/256 |
| PCIe 3.0 | 8/16 | 16/32 | 32/64 | 64/128 | 96/192 | 128/256 | 256/512 |
| PCIe 4.0 | 16/32 | 32/64 | 64/128 | 128/256 | 192/384 | 256/512 | 512/1024 |
Примеры PCI Express устройств
В первую очередь PCI Express используется для подключения дискретных видеокарт. С момента появления данной шины абсолютно все видеокарты используют именно ее.

Видеокарта GIGABYTE GeForce GTX 770
Однако это далеко не все что умеет шина PCI Express. Ее используют производители других комплектующих.

Звуковая карта SUS Xonar DX

SSD накопитель OCZ Z-Drive R4 Enterprise
Алексей Борзенко
,
к.т.н., доцент РРТА
Интерфейс PCI Express (известный прежде под названием 3GIO) основан на открытых стандартах и выступает как наследник PCI и его вариантов для систем ввода-вывода серверов и клиентских устройств. В отличие от PCI и PCI-X, основанных на 32- и 64-разрядной параллельной шине, PCI Express использует высокоскоростную технологию последовательного соединения, похожую на ту, что используется в Gigabit Ethernet, Serial ATA (SATA) и Serial Attached SCSI (SAS). PCI Express отражает общую для компьютерной индустрии тенденцию замены устаревших параллельных общих шин на высокоскоростные последовательные соединения типа "точка-точка" (point-to-point).
Новая технология шины обеспечивает скорость передачи, которая будет достаточной с учетом развития процессоров и подсистем ввода-вывода, по крайней мере, в течение следующих 10 лет.
По сравнению с PCI технология PCI Express имеет следующие преимущества:
- высокая пропускная способность - в первой версии теоретическая пиковая пропускная способность составит 5-80 Гбит/с, в зависимости от реализации;
- последовательное соединение, обеспечивающее масштабирование производительности;
- отдельное соединение "точка-точка" для каждого устройства вместо общей шины PCI;
- малые задержки для серверной архитектуры;
- меньший размер разъемов и упрощенное проектирование систем;
- расширенные функции.
В течение следующего десятилетия интерфейс PCI Express постепенно заменит параллельные шины PCI, PCI-X и AGP. Сначала он вытеснит шины, которые требуют дополнительной производительности и функций. Например, первоначально PCI Express будет применяться как замена шины передачи графических данных AGP 8X в клиентских системах, обеспечивая высокую полосу пропускания и поддержку мультимедийного трафика. Он будет сосуществовать с шиной PCI-X и постепенно вытеснять ее в серверных системах.
Шина PCI
Шина PCI, появившаяся в 1992 г., стала основой системы ввода-вывода практически для всех компьютерных платформ. Первоначальная 33-МГц, 32-разрядная реализация обеспечивала теоретически возможную пиковую производительность 133 Мбайт/с. В последующие годы архитектура платформы развивалась, различные функции перекладывались на варианты PCI с более высокой пропускной способностью (табл. 1), включая AGP и PCI-X.
Таблица 1. Пропускная способность шин PCI, PCI-X и AGP
| Шина и частота | Пиковая пропускная способность, Мбайт/с | |
| в 32-разрядном режиме | в 64-разрядном режиме | |
| PCI 33 МГц | 133 | 266 |
| PCI 66 МГц | 266 | 532 |
| PCI-X 100 МГц | Не поддерживает | 800 |
| PCI-X 133 МГц | Не поддерживает | 1 Гбайт/с |
| AGP 8X | 2,1 Гбайт/с | Не поддерживает |
Если внимательно изучить применяемую в PCI технологию передачи сигналов, станет ясно, что увеличить производительность этой многоточечной параллельной шины уже невозможно. Дело в том, что для шины PCI трудно реализовать наращивание частоты или уменьшение напряжения. Кроме того, она не поддерживает такие функции, как расширенное управление энергопотреблением, замена и подключение в горячем режиме периферийных устройств и функции качества сервиса - QoS (а проще говоря, доступности) для гарантированной полосы пропускания операций в реальном времени. Наконец, вся имеющаяся полоса пропускания шины PCI не поддерживает одновременную передачу данных в обоих направлениях. Многие сети передачи данных обеспечивают параллельный трафик, благодаря чему задержка при передаче сообщений сводится к минимуму.
Клиентские системы
Первый вариант шины PCI был разработан для поддержки 2D-графики, высокопроизводительных жестких дисков и локальных сетей. Вскоре после появления PCI выросшие требования к пропускной способности графической подсистемы 3D превысили возможности 32-разрядной шины PCI с частотой 33 МГц. Чтобы решить эту проблему, корпорация Intel (http://www.intel.com) вместе с несколькими производителями графических плат разработали спецификацию AGP, описывающую выделенную высокоскоростную шину для работы с графикой. Шина AGP освободила систему PCI от передачи графики, что позволило задействовать ее пропускную способность для других операций передачи данных и ввода-вывода. Кроме того, впоследствии Intel добавила выделенные каналы USB 2.0 и Serial ATA к южному мосту своих наборов микросхем (НМС), что дополнительно уменьшило нагрузку ввода-вывода на шину PCI. На рис. 1 показана внутренняя архитектура типичной клиентской системы ПК и пропускная способность шины ввода-вывода и графики.
Узкие места клиентских систем
Есть несколько шин клиентской системы, способных ограничивать производительность из-за постоянного совершенствования центрального процессора, памяти и устройств ввода-вывода: шина PCI, шина AGP и канал между северным и южным мостами.
PCI Bus. Шина PCI обеспечивает скорость передачи до 133 Мбайт/с для подключенных устройств ввода-вывода. Ряд устройств ввода-вывода способны загрузить значительную часть этой полосы пропускания, так что если подключить несколько таких устройств, то общая шина PCI не сможет справиться с трафиком.
На рис. 2 показаны требования к полосе пропускания разных сетевых протоколов, видеоприложений и внешних устройств, которые обслуживает шина PCI. Как видно, многоточечная общая шина PCI с трудом способна работать с современными устройствами. Проблема обостряется с появлением новых периферийных устройств, использующих еще более высокую скорость передачи.
Например, для Gigabit Ethernet нужна полоса пропускания 125 Мбайт/с, иными словами, этот сетевой протокол фактически полностью загружает шину PCI 133 Мбайт/с. У IEEE 1394b максимальная полоса пропускания составляет 100 Мбайт/с, и он также полностью загружает стандартную PCI-шину.
AGP. В последнее десятилетие требования к производительности видео удваивались каждые два года. За этот период шина передачи графики перешла от PCI к AGP, затем от AGP к AGP 2X, AGP 4X и, наконец, к сегодняшней AGP 8X.
AGP 8X работает на скорости 2,134 Гбайт/с. Несмотря на такую полосу пропускания, постепенный рост требований к производительности шины AGP создает значительные проблемы при проектировании плат и повышает стоимость соединений. Как и в случае шины PCI, расширение возможностей шины AGP становится все сложнее и дороже по мере роста частот.
Канал между северным и южным мостами. Нагрузка на шину PCI влияет и на связь между северным и южным мостами, особенно при использовании дисков SATA и устройств USB. В будущем здесь потребуется канал с большей полосой пропускания.
Серверные системы
В серверах первоначальная 32-разрядная, 33-МГц шина PCI была расширена до 64-разрядной 66-МГц с пропускной способностью 532 Мбайт/с. Частота 64-разрядной шины была увеличена до 100 и до 133 МГц - этот вариант называется PCI-X. Такая шина соединяет НМС серверной системы (или двухпроцессорной рабочей станции класса high-end) со слотами расширения, контроллерами Gigabit Ethernet и Ultra320 SCSI, интегрированными на системной плате. 64-разрядная шина PCI-X с частотой 133 МГц обеспечивает пиковую полосу пропускания 1 Гбайт/с между НМС системы и устройством ввода-вывода. Сейчас этого достаточно для большинства операций ввода-вывода, включая протоколы Gigabit Ethernet, Ultra320 SCSI и Fibre Channel 2 Гбит/с. Однако PCI-X, как и PCI, - это общая шина с присущими ей недостатками.
Группа PCI Special Interest Group (PCI SIG, http://www.psisig.com) разработала спецификацию PCI-X 2.0, описывающую 64-разрядную, 266-МГц шину PCI-X, у которой скорость передачи вдвое больше, чем у 133-МГц PCI-X. Тем не менее при использовании расширенного варианта параллельной шины PCI-X возникают серьезные проблемы с проектированием. Разъемы для нее громоздкие и дорогие, а строгие требования к проектированию значительно повышают стоимость системных плат по мере роста частот. Кроме того, на высоких частотах допускается подключение к шине PCI-X 2.0 только одного устройства ввода-вывода в конфигурации "точка-точка".
Узкие места серверных систем
На рис. 3 показаны внутренние системные межсоединения в типичной двухпроцессорной серверной системе. В этой архитектуре расширение полосы пропускания обеспечивается с помощью фирменного интерфейса между микросхемами северного моста и моста PCI-X. Несколько шин PCI-X подключаются к высокоскоростным слотам расширения, 10-Гбит Ethernet и дискам SAS/SATA. Но эта архитектура имеет несколько недостатков. Специальные кристаллы мостов PCI-X соединяют несколько параллельных шин PCI-X со специальным последовательным межсоединением НМС. Такой подход связан с высокими затратами, неэффективен и приводит к задержке передачи между устройствами ввода-вывода и северным мостом. Например, этот подход предусматривает соединение последовательной фабрики 10 Гбит/с с 64-разрядной параллельной шиной, которая, в свою очередь, подключается через фирменный кристалл моста PCI-X к последовательному межсоединению в северном мосте.
 |
Рис. 3. Современная двухпроцессорная архитектура процессора. |
Кроме того, технология внешнего ввода-вывода в серверах нового поколения требует намного более широкой полосы пропускания, чем способна обеспечить 133-МГц шина PCI-X. Эти технологии включают такие фабрики, как 10-Гбит Ethernet, Fibre Channel 10 Гбит/с и 4x Infiniband, а также будущие высокоскоростные интерфейсы жестких дисков - SATA и SAS 3 Гбит/с. В случае фабрики 10 Гбит/с каждый порт с пропускной способностью 10 Гбит/с может передавать данные в обоих направлениях с пиковой скоростью 2 Гбайт/с, а 133-МГц шина PCI-X обеспечивает максимальную скорость 1 Гбайт/с в одном направлении в один момент времени. Это означает, что 133-МГц шина PCI-X способна обработать пиковую пропускную способность таких фабрик не более чем на 50%.
Хотя PCI-X 2.0 с частотой 266 МГц удвоит ширину пиковой полосы пропускания PCI-X - до 2 Гбайт/с, ее все же будет недостаточно для суммарных 4 Гбайт/с, которые нужны двухпортовому контроллеру фабрики 10 Гбит/с. Ясно, что клиентским системам и серверам требуется замена параллельной шины PCI и ее вариантов.
PCI Express
PCI Express предоставляет масштабируемую высокоскоростную последовательную шину ввода-вывода. Многоуровневая архитектура PCI Express поддерживает существующие приложения PCI и драйверы за счет обратной совместимости с существующей моделью PCI. В частности, архитектура PCI Express определяет высокопроизводительную масштабируемую последовательную шину "точка-точка". Канал PCI Express состоит из двух однонаправленных каналов, каждый из которых реализован как пара передачи и пара приема для одновременной передачи в обоих направлениях. Каждая пара состоит из двух низковольтных пар дифференциальных сигналов. Таймер синхронизации встроен в каждую пару и использует схему кодировки для синхронизации 8b/10b, позволяя достичь высокой скорости передачи данных. На рис. 4 представлены каналы PCI в сравнении с PCI Express.
 |
| Рис. 4. PCI в сравнении с PCI Express. |
Многоуровневая архитектура PCI ExpressУровень Конфигурация/ОС определяет стандартный механизм (в соответствии со спецификацией PCI Plug-and-Play) инициализации устройств, их нумерацию и конфигурирование. Этот уровень общается с уровнем ПО, инициирующего передачу данных между периферийными устройствами или получение данных от подключенной периферии. Интерфейс PCI Express разрабатывался как совместимый с существующими ОС, но для поддержки мощных функций технологии потребуются ОС будущего времени. Уровень Программное обеспечение генерирует запросы чтения и записи к периферийным устройствам. PCI Express обеспечивает инициализацию и совместимость с ПО PCI. Как и в PCI, модель инициализации PCI Express позволяет ОС обнаруживать новые аппаратные устройства и распределять ресурсы системы. PCI Express сохраняет пространство конфигурирования PCI и программирование устройств ввода-вывода, и все ОС будут загружаться, не требуя модификации, в системах с использованием PCI Express. Сохраняется и модель выполнения ПО PCI, что позволяет запускать существующее ПО без всякой модификации. Уровень Транзакций читает и записывает запросы от уровня ПО к канальному уровню с помощью протокола на основе пакетов и обеспечивает соответствие ответных пакетов запросам ПО. Этот уровень поддерживает 32-разрядную и расширенную 64-разрядную адресацию памяти, адресное пространство PCI памяти, ввода-вывода и конфигурации, а также новое пространство сообщений для таких сообщений, как прерывания и сбросы. Канальный уровень добавляет последовательность пакетов и обнаружение ошибок на основе циклических кодов избыточности (CRC) к пакетам данных, создавая надежный механизм передачи данных между системным НМС и контроллером ввода-вывода. Физический уровень базируется на двойных однонаправленных каналах PCI Express. Это обеспечивает гибкость и позволяет использовать разные технологии и частоты. Благодаря такому подходу первоначальную кремниевую технологию можно будет со временем заменить инновациями, которые сохранят обратную совместимость. Например, для повышения скорости передачи данных можно использовать оптоволоконную технологию. Механический уровень определяет форм-факторы периферийных устройств.
|
Ширину пропускания канала PCI Express можно масштабировать за счет добавления сигнальных пар для формирования нескольких линий между двумя устройствами. Спецификация поддерживает ширину линии x1, x4, x8 и x16 и соответственно расщепляет байты данных по линиям. После того, как два агента на обоих концах канала PCI Express договорятся о ширине линии и частоте передачи, байты данных передаются расщепленными по линиям с кодировкой.
Базовый канал x1 имеет пиковую "сырую" полосу пропускания на уровне 2,5 Гбит/с. Поскольку шина работает в двух направлениях (данные могут одновременно передаваться в обоих направлениях), эффективная "сырая" скорость передачи равна 5 Гбит/с. В табл. 2 приведены скорости передачи данных с кодированием и без кодирования при реализации линий x1, x4, x8 и x16, которые определены в первой версии PCI Express.
Таблица 2. Полоса пропускания PCI Express
В будущих реализациях PCI Express частота передачи данных по каналу еще больше увеличится. Например, после появления второго поколения PCI Express частота передачи вырастет не менее чем вдвое. Благодаря архитектуре "точка-точка" вся полоса пропускания каждой шины PCI Express выделяется устройству на конце канала. Несколько устройств PCI могут работать одновременно, не мешая друг другу.
PCI Express, в отличие от PCI, имеет минимальные сигналы боковой полосы, а временные метки и информация об адресе встроены в данные. Именно поэтому данная технология обеспечивает высокую полосу пропускания на один контакт разъема ввода-вывода по сравнению с PCI (рис. 5). В результате соединители становятся более эффективными, компактными и дешевыми.
Технология PCI Express надежно обеспечивает более высокие скорости передачи данных за счет низковольтных дифференциальных сигналов. При таком подходе сигнал идет от источника к получателю по двум линиям: по одной посылается "позитивный" образ, по другой - "негативный", или "перевернутый" образ сигнала. Из-за строгих правил маршрутизации шум, влияющий на одну линию, влияет и на другую. Приемник получает оба сигнала, инвертирует негативную версию обратно в позитивную и суммирует два собранных сигнала, в результате шумы эффективно удаляются.
В первоначальной спецификации PCI Express определены графические платы мощностью до 75 Вт. Сейчас разрабатывается новая спецификация графики PCI Express для карт мощностью до 150 Вт. Эти характеристики соответствуют требованиям графических адаптеров, для которых сейчас предел мощности составляет 41 Вт для массовых карт AGP и 110 Вт для карт AGP Pro 110.
Полоса пропускания PCI ExpressПолоса пропускания PCI Express обычно обозначается как "кодированная" полоса пропускания. PCI Express использует кодировку 8b/10b, которая транслирует 8-разрядные данные в 10-битную последовательность передаваемых символов. Этот подход улучшает физический сигнал, что облегчает синхронизацию битов, упрощает проектирование приемников и передатчиков, совершенствует обнаружение ошибок и позволяет отличить управляющие символы от символов данных. Ширина "кодированной" полосы пропускания базовой линии x1 PCI Express равна 5 Гбит/с. Однако более точную цифру дает полоса пропускания "без кодировки", ширина которой составляет 80% "кодированной", т. е. 4 Гбит/с. В табл. 2 приведена полоса пропускания PCI Express с кодировкой и без нее. |
Расширенные функции PCI Express
В PCI Express предусмотрены расширенные функции, которые будут постепенно реализовываться по мере их поддержки ОС и устройствами, а также по мере их использования приложениями. В список этих функций входят:
- расширенное управление энергопотреблением;
- поддержка трафика данных в реальном времени;
- горячая замена;
- целостность данных и обработка ошибок.
Расширенное управление энергопотреблением
Управление в PCI Express позволяет уменьшить энергопотребление, если шина не активна (т. е. данные не пересылаются между компонентами и периферийными устройствами). Интерфейс PCI Express должен быть активным все время, чтобы передатчик и получатель работали синхронно. Для этого, если нет данных для передачи, непрерывно посылаются пустые символы, получатель декодирует их и отбрасывает. Этот процесс потребляет дополнительную энергию, что, в частности, уменьшает время работы от батарей ноутбуков и карманных компьютеров.
Для решения этой проблемы спецификация PCI Express определяет два состояния канала с низким энергопотреблением и протокол Active-State Power Management (ASPM). Когда канал PCI Express не используется, он может перейти в одно из двух состояний с низким энергопотреблением. Эти состояния экономят энергию, но требуют времени на восстановление для ресинхронизации передатчика и получателя, когда нужно передать данные. Чем дольше время восстановления (или запаздывания), тем ниже энергопотребление.
Поддержка трафика реального времени
PCI Express, в отличие от PCI, поддерживает изохронную (или зависимую от времени) передачу данных и разные уровни QoS. Эти функции реализованы с помощью "виртуальных каналов", которые гарантируют, что конкретные пакеты данных прибудут по своему конечному адресу в определенный момент времени. PCI Express поддерживает несколько изохронных виртуальных каналов (каждый с независимым сеансом связи) на одну линию. Все эти каналы могут иметь разную доступность. Данное законченное решение предназначено для приложений, требующих доставки данных в реальном времени (такова, например, работа с аудио и видео в реальном времени).
Горячая замена
Системы на базе PCI не имеют встроенной поддержки горячей замены плат ввода-вывода. Уже после выпуска стандарта PCI как дополнение к нему была разработана функция горячей замены серверных карт и PC Card с ограниченными возможностями. Эти решения рассчитаны на растущие требования серверов и портативных компьютеров. Во-первых, часто трудно или невозможно запланировать отключение сервера для замены или установки периферийных карт. Возможность горячей замены устройств ввода-вывода сводит к минимуму простои. Во-вторых, пользователям ноутбуков нужно заменять в горячем режиме карты, обеспечивающие такие функции ввода-вывода, как мобильный диск и работа в сети.
В PCI Express реализована оригинальная поддержка для горячей замены периферии ввода-вывода. Единая программная модель может использоваться для всех форм-факторов PCI Express.
Целостность данных и обработка ошибок
Интерфейс PCI Express поддерживает целостность данных на уровне каналов для всех типов пакетов транзакций и каналов данных. Благодаря этому обеспечивается целостность данных при их передаче для приложений высокой доступности, особенно для выполняющихся на серверных системах. PCI Express также поддерживает обработку ошибок PCI и использует усовершенствованный механизм оповещения об ошибках и их обработки, что расширяет возможности решений для изоляции сбоев и восстановления работоспособности.
Форм-факторы PCI Express
Разработаны различные форм-факторы PCI Express, предназначенные для клиентских систем, серверов и портативных компьютеров. В их числе стандартные и низкопрофильные карты - для настольных ПК, рабочих станций и серверов, Mini Card - для портативных компьютеров, ExpressCard - для портативных и настольных ПК, а также модули Server I/O Module (SIOM).
Стандартные и низкопрофильные карты
Выпускаемые сейчас стандартные и низкопрофильные карты PCI используются на различных платформах, включая серверы, рабочие станции и настольные ПК. PCI Express также определяет стандартные и низкопрофильные карты, которые могут заменить устаревшие карты PCI и сосуществовать с ними. Эти карты имеют те же размеры, что и карты PCI, и оборудованы задними скобами для внешних кабельных соединений.
Карты PCI и PCI Express отличаются соединителями ввода-вывода - разъем x1 PCI Express имеет 36 контактов, а у стандартного соединителя PCI их 120.
Коннектор x1 PCI Express намного меньше, чем у карты PCI Card. Рядом с разъемом PCI Express расположена маленькая заглушка, которая не позволяет вставить его в слот PCI. Стандартные и низкопрофильные форм-факторы также поддерживают реализации x4, x8 и x16. На рис. 6 показаны размеры соединителей PCI в сравнении с разъемами PCI, AGP 8X и PCI-X, которые они заменят на системной плате.
В табл. 3 приведены требования к совместимости для стандартных и низкопрофильных карт PCI Express. Карта x1 может использоваться во всех четырех слотах системной платы: x1, x4, x8 и x16. Когда карта x1 вставляется в слот с более высокой скоростью, канальный уровень снижает скорость канала до x1.
Таблица 3. Совместимость карт PCI Express Card
| Реализация PCI Express | Слот x1 | Слот x4 | Слот x8 | Слот x16 |
| Карта x1 | Нужна | Нужна | Нужна | Нужна |
| Карта x4 | Нет | Нужна | Допускается | Допускается |
| Карта x8 | Нет | Допускается* | Нужна | Допускается |
| Карта x16 | Нет | Нет | Нет | Нужна |
| *Эта реализация будет иметь коннектор x8 на слоте x4, т. е.
в такой слот можно вставлять карты x8, которые, однако, будут работать на скорости x4. |
||||
Переход на карты PCI Express
Платы клиентских систем будут постепенно переходить от соединителей PCI к соединителям x1 PCI Express. Рабочие станции соответственно будут переходить от PCI на разъемы x1 PCI Express и от PCI-X - к x4 PCI Express. Соединитель AGP 8X будет заменяться разъемом x16 PCI Express. В отличие от AGP, он может использоваться для других карт PCI Express, если не требуется графическая карта PCI Express.
Серверы будут постепенно переходить от соединителей PCI-X в основном на x4 и x8. Использование в серверных системах комбинации слотов PCI Express и PCI/PCI-X позволит покупателям адаптироваться к новой технологии при сохранении поддержки унаследованных систем.
Рассмотрим пример типичной современной клиентской системы и переходной системной платы PCI Express. Системная плата PCI содержит пять стандартных слотов PCI и один слот AGP. Системная плата PCI Express также имеет шесть слотов ввода-вывода, но только три из них - слоты PCI, а еще два - это соединители x1 PCI Express и один - разъем x16 PCI Express, заменяющий слот AGP 8X. Соединители PCI Express на системной плате иногда делают черными, чтобы отличить их от белых слотов PCI и коричневых AGP.
Конечно, первыми устройствами, которые перейдут на карты PCI Express, станут платы с повышенными требованиями к полосе пропускания. В клиентских системах это графические адаптеры, адаптеры стандарта IEEE 1394, Gigabit Ethernet и ТВ-тюнеры, а в серверных системах - карты Ultra320 SCSI RAID, HBA-адаптеры Fibre Channel и карты Gigabit Ethernet и 10 Gigabit Ethernet. Ожидается, что стоимость этих плат будет сравнима с ценой аналогичных PCI-X, а в некоторых случаях даже меньше. Другие карты также постепенно перейдут на PCI Express, но может потребоваться несколько лет, прежде чем недорогие карты, работающие с низкой пропускной способностью (например, модемы), начнут использовать эту технологию. Таким образом, как это было и с переходом от ISA к шине PCI, еще долгие годы PCI и PCI Express будут сосуществовать.
PCI Express Mini Card
PCI Express Mini Card заменят Mini PCI, представляющие собой маленькую внутреннюю плату, по своей функциональности аналогичную картам PCI для настольных ПК. Карты Mini PCI используются в основном для реализации сетевых функций в портативных компьютерах, выпускаемых серийно или на заказ. По размерам PCI Express Mini Card вдвое меньше Mini PCI, что позволяет проектировщикам ноутбуков предусмотреть место для одной или двух карт в зависимости от размера компьютера.
PCI Express Mini Card может использовать PCI Express и/или USB 2.0. Разъем PCI Express Mini Card на системной плате должен поддерживать как канал x1 PCI Express, так и USB 2.0. Поддержка USB 2.0 облегчит переход на PCI Express, потому что производителям периферии нужно определенное время для реализации поддержки PCI Express в своих наборах микросхем. В переходный период PCI Express Mini Card можно будет легко подключать с помощью USB 2.0.
ExpressCard
ExpressCard - это маленькая модульная дополнительная карта, которая в течение следующих лет должна заменить PC Card. Спецификация ExpressCard была разработана ассоциацией Personal Computer Memory Card International Association (PCMCIA, http://www.pcmcia.org). Форм-фактор ExpressCard обеспечивает замену PC Card с меньшими размерами и стоимостью и более высокой производительностью. Как и PCI Express Mini Card, модуль ExpressCard поддерживает каналы x1 PCI Express и USB 2.0. Низкая цена делает его оптимальным для настольных систем с уменьшенным форм-фактором. Модуль ExpressCard также имеет пониженное энергопотребление, и его можно вставлять в горячем режиме. Скорее всего, ExpressCard будут использоваться в сетевых платах, жестких дисках и будущих технологиях ввода-вывода.
PCI Express Server I/O Module
Массовое появление модулей SIOM ожидается после выхода второго поколения PCI Express. PCI Express SIOM обеспечивает форм-фактор, который легко установить и заменить. Он будет модульным, что позволит устанавливать и обслуживать карты ввода-вывода без прерывания работы системы и не открывая корпус компьютера.
SIOM предусматривает более радикальное изменение форм-фактора, чем другие варианты PCI Express. Он решит многие проблемы с серверными картами PCI и PCI-X. Конструкция SIOM делает карты более надежными, что особенно важно в центрах обработки данных. Модуль также разрабатывался с расчетом на принудительную вентиляцию, поскольку мощным серверам свойственно высокое тепловыделение. Потоки охлаждающего воздуха могут идти сзади, сверху или снизу модуля. Такая гибкость дает проектировщикам систем больше свободы при оценке вариантов охлаждения стоечных систем, оборудованных SIOM.
Модули SIOM с самым большим форм-фактором способны выполнять сравнительно сложные функции и использовать весь диапазон каналов PCI Express.
Примеры систем с PCI Express
Рассмотрим, как технология PCI Express может быть реализована в клиентской и серверной системах. Первоначально канал x16 PCI Express заменит шину AGP между графической подсистемой и северным мостом. Вариант PCI Express может заменить и канал между обоими мостами НМС. Предусмотрено также несколько каналов PCI Express от южного моста к контроллеру сетевого интерфейса (NIC), устройствам IEEE 1394 и другой периферии. Южный мост будет по-прежнему поддерживать устаревшие слоты PCI.
Такая архитектура дает покупателям несколько важных преимуществ. Настольные системы еще долго будут оснащаться шинами как PCI, так и PCI Express. Первые поколения серверов PCI Express также будут иметь слоты PCI-X для устаревших карт PCI-X. Чтобы упростить переход, предусмотрена защита от ошибочной установки PCI в слоты PCI Express и карт PCI Express - в слоты PCI. Кроме того, PCI Express обеспечивает широкое применение карт Gigabit Ethernet, 10 Gigabit Ethernet, 1394b и других высокоскоростных устройств в клиентских системах. Он также поддерживает растущие требования к полосе пропускания графических подсистем.
PCI Express может применяться в двухпроцессорной серверной архитектуре, значительно упрощая систему. Каналы PCI Express для устройств ввода-вывода и слотов подключаются непосредственно к северному мосту. Такой подход дает ряд преимуществ. Во-первых, это высокая полоса пропускания для ввода-вывода следующего поколения, например, 10 Gigabit Ethernet и фабрики x4 Infiniband. Например, канал x8 PCI Express способен обеспечить пиковую полосу пропускания, которая требуется двухпортовому контроллеру 10 Гбит/с.
Во-вторых, меньше становятся расходы на внедрение. Удается подключить к системному набору микросхем больше слотов и встроенных устройств ввода-вывода, что уменьшает число микросхем моста и снижает требования к маршрутизации сигналов на системной плате. И наконец, за счет отказа от использования микросхемы моста PCI-X уменьшается запаздывание передачи между устройствами ввода-вывода и центральным процессором и памятью.
Таким образом, технология PCI Express обеспечивает надежное и масштабируемое последовательное соединение, обратно совместимое с PCI. Как и PCI, она будет использоваться в широком спектре существующих платформ, включая серверы, портативные компьютеры, настольные системы и рабочие станции. Она также позволит реализовать новаторскую конструкцию модульных компьютерных систем.
Сергей Селиванов,
Совсем немного времени осталось до появления новых чипсетов Intel, а вместе с ними придет и новый стандарт – PCI Express. О том, что это, какими преимуществами и недостатками обладает, вы можете узнать из этой статьи.
Любая компьютерная технология проходит свой путь от рождения, триумфа к свалке истории. Все бы ничего, да каждое очередное нововведение, как правило, чревато серьезным перетряхиванием системных блоков и неопределенностью в умах пользователей – пора или еще подождать с апгрейдом? Тем более огромными кажутся все новшества, которые свалятся на головы покупателей в нынешнем году. Такого всестороннего разрушительного действия на основы платформы не было уже давно - сменятся процессорные разъемы (у Intel настанет время Socket 775, у AMD, соответственно, Socket 939); к концу года действительно новой будет называться система лишь с 240-контактными модулями DDR2; вдогонку ко всему этому близится появление новых форм-факторов самих плат – BTX. Но самым радикальным все же станет низвержение старых привычных элементов ландшафта системной платы – разъемов PCI и AGP, которым приходит время сказать последнее "прости-прощай".
Новое поколение технологий приносит новые скорости и новые технологические решения. Правда, на деле случалось не раз, что революционные нововведения оказывались не всегда своевременными и не такими уж полезными, как красиво заявлялось при их выпуске. Традиционно, отдуваться за эксперименты приходится конечному покупателю. Примеров самых передовых, но неоцененных или невостребованных технологий можно привести множество – шина EISA, память RDRAM, слоты AMR/CNR и многое другое.
Не касаясь тупиковых ветвей эволюции ПК, сегодня стоит поговорить о своевременности внедрения новых технологий на примере шины PCI Express. Сегодня можно с уверенностью сказать, что от перехода на этот шинный стандарт никуда не деться. Попробуем рассмотреть ключевые особенности новоявленной шины, ее сходства и отличия от распространенных сейчас PCI и AGP.
Немного истории
Первые разработки шины PCI, стартовавшие в начале 90-х годов, были призваны избавиться от множества присутствовавших на тот момент несовместимых шинных интерфейсов – VLB (VESA Local Bus), EISA, ISA и Micro Channel. Наряду с этим преследовалась цель избавиться от тяжкого наследия фрагментированной шины ISA и впервые добиться соединений класса "чип-чип".
На момент появления в 1993 году базовой версии шины Peripheral Component Interconnect (PCI) - IEEE P1386.1, предусматривались революционные усовершенствования: расширение шины данных до 32 бит, поддержка адресации до 4 ГБ данных (32 бита), а также использование режима синхронного обмена данными. По тем временам тактовая частота шины 33 МГц удовлетворяла условиям работы с периферией в настольных и серверных системах, все были довольны. Последовавший за этим резкий скачок тактовых частот процессоров и памяти привел к увеличению тактовой частоты PCI до 66 МГц, хотя, тактовые частоты процессоров за этот же период скакнули с 33 МГц до 3,0+ ГГц. Все последующие варианты PCI – AGP, PCI-X, MiniPCI, CardBus, несмотря на привнесение определенных дополнений, например, иных форм-факторов разъемов, новых сигнальных уровней и даже передачи данных по фронтам импульса (Double Data Rate/ Quadruple Data Rate), тем не менее, несли в себе ограничения, накладываемые самой топологией интерфейса.
Возможности наращивания пропускной способности шины PCI за счет увеличения тактовой частоты без усложнения схем разводки и соответствующего адекватного удорожания к настоящему времени исчерпаны полностью. А ведь на очереди появились такие актуальные интерфейсы, как 1/10 Gigabit Ethernet, IEEE 1394B, которые полностью выбирают пропускную возможность шины одним устройством и даже выходят за эти рамки. PCI душит рост скорости периферии, критичными становятся ограничения по числу сигнальных контактов шины, торможение процессов реального времени и требования по энергосбережению современных ПК. Если вспомнить наиболее производительные версии шины PCI, например, серверную PCI-X и графическую AGP, то в этом случае мы упираемся в укорачивание проводников шины за счет высокой частоты, требование к установке своего контроллера на каждый слот и достаточно высокую стоимость ее реализации.
Грядет тотальное торжество последовательных шин
Итого, параллельные шины себя исчерпали, рано или поздно взоры разработчиков должны были обратиться в сторону последовательных. Так оно и есть, в результате чего практически все современные индустриальные интерфейсы к настоящему времени перебрались на такой принцип обмена данными. Взгляните на приведенную ниже таблицу: речь идет не только о сетевых интерфейсах, которым на роду написано быть последовательными; все остальные ключевые шины уже имеют последовательную природу.
Архитектуру PCI Express можно рассматривать послойно, в сравнении с адресной моделью PCI. Конфигурация PCI Express является стандартной для устройств, определенных plug-and-play спецификациями PCI: программный уровень генерирует запросы чтения/записи, уровень транзакций транспортирует эти запросы к периферийным устройствам с помощью разделенного пакетного протокола. Для поддержания высокой производительности шины соединительный (link) уровень добавляет пакетам очередность и CRC; базовый физический уровень состоит из двойного симплексного канала, осуществляющего функции приемной и передающей пары. Таким образом, исходная скорость 2,5 Гб/с в каждом направлении позволяет говорить о создании дуплексного коммуникационного канала производительностью до 200 МБ/с, что в четыре раза превышает возможности классической шины PCI.
Рассматривая процессы, протекающие в шине на сигнальном уровне, нельзя не отметить уникальные плюсы PCI Express - значительное снижение затухания в линиях передачи и повышенная чувствительность приемной части интерфейса. Из чего напрашивается вывод о менее критичных требованиях к импедансу входных цепей, а также возможность увеличения длины разводки проводников шины - в нынешней версии стандарта PCI-E они лимитируются 12 дюймами для системных плат, 3,5 дюймами для контроллеров и 15 дюймами для межчиповых соединений. При этом не предъявляется никаких дополнительных требований к технологии разводки печатной платы: могут использоваться как обычные 4-слойные PCB толщиной 0,062 дюйма, так и варианты с шестью и более слоями.
|
|

Теоретически, требования, выдвигаемые стандартом PCI Express, с легкостью могут быть адаптированы для нужд устройств любого уровня – от мобильного телефона до сервера уровня предприятия, а также, в перспективе, могут быть переложены для применения других физических типов носителей. Именно такая гибкость и необходима для интерфейса, собирающегося прослужить стандартом ближайшее обозримое будущее.
Использование новых разъемов и других конструктивных возможностей, оговоренных спецификациями нового стандарта, позволяет говорить об увеличении энергопотребления конечных контроллеров до 75 Вт (при токе до 5,5 А)!
Системы питания компьютеров с поддержкой разных вариантов PCI Express отличаются от привычных нам спецификаций ATX12 и, скорее, схожи с требованиями, предъявляемыми к питанию серверных систем. Так, привычный 20-контактный разъем питания ATX удлиняется и в нем появляются четыре дополнительных контакта, как раз для усиления силовых шин +12 В, 5,0 В и +3,3 В. Соответственно, до 75 Вт повышаются ограничения на питание одного слота в BIOS. При этом нижняя граница мощности для блоков питания устанавливается на уровне примерно 300 Вт. Словом, хотя изменения в цепях питания и не носят такой радикальный характер, как при переходе с AT на ATX, с мыслью о неминуемом апгрейде БП придется свыкнуться.
|
|

Варианты PCI Express: их будет много
Версии PCI Express будут внедряться в зависимости от ставящихся перед интерфейсом задач и типом устройства. Например, серверы, где востребована максимальная пропускная способность, будут оборудованы максимальным количеством слотов PCI Express с максимальными показателям. В то же время, для нужд ноутбуков в большинстве случаев будет достаточно архитектуры PCI Express x1. Для настольных ПК и рабочих станций понадобится комбинация из различных вариантов реализации шины.
Несмотря на то, что новый стандарт дает некую свободу конечным производителям при разработке крепежа, жестко оговоренными остаются следующие требования: энергопотребление – не более 75 Вт, вес – не более 350 граммов, высота – не более 115,15 мм.
|
|

Конечно, под такими монстрами прозрачно подразумеваются графические карты с интерфейсом PCI Express 16x; во всех других случаях требования к крепежу и другим характеристикам контроллеров значительно скромнее.
Особняком стоит реализация PCI Express для мобильных устройств в виде стандарта ExpressCard. Первыми поддержку модулей этого подстандарта получат ноутбуки и миниатюрные настольные ПК, хотя, уже известны случаи представления концепций серверных плат с разъемом ExpressCard. основное преимущество применения таких модулей - подключение периферии практически без нужды использования крепежного инструмента, а также инсталляции дополнительных драйверов. Технология ExpressCard заменит собой все устаревшие параллельные шины, в результате останутся только три современных интерфейса - PCI Express, USB 2.0 и FireWire.
|
|

В настоящее время разработано два форм-фактора модулей ExpressCard – ExpressCard/34 (ширина 34 мм) и ExpressCard/54 (ширина 54). Оба модуля имеют высоту 5 мм, как у стандарта PC Card Type II; длина модулей 75 мм, что на 10,6 мм меньше, чем у PC Card. При этом, модули ExpressCard/34 и ExpressCard/54 обладают одинаковым интерфейсом. Каждый слот под модули ExpressCard может обслуживать шину PCI Express x1.
Преимущества PCI Express
Сравнивая возможности господствовавшей многие годы параллельной шины PCI и архитектуру PCI Express, можно выделить пять наиболее значимых преимуществ последней:
Высокая производительность – повышение пропускной способности версии x1 как минимум вдвое по сравнению с PCI, возможность линейного наращивания производительности путем линейного расширения шины. Помимо этого, PCI Express является реально дуплексной шиной.
Упрощение разводки периферии – стандартизация там, где ранее использовались всевозможные варианты PCI - AGP, PCI-X и др.; снижение комплексных затрат на разработку и внедрение систем.
Уровневая архитектура – основные затраты на развитие PCI Express в дальнейшем ложатся лишь на разработку соответствующей обвязки, можно экономить на возможности работы с прежним программным обеспечением.
Следующее поколение периферии – PCI Express позволяет реализовать новые возможности обмена данными и мультимедийным контентом за счет изохронной природы передачи (т.е. разнесения отдельных частей сигнала по времени).
Простота использования – производить апгрейд и доработку систем устройствами PCI Express станет значительно легче. Теперь появится возможность использовать PCI Express карты с "горячим" подключением.
В заключение попробуем ответить на заданный в начале вопрос – действительно, своевременно ли появление PCI Express? Тональность ответа явно будет разной в зависимости от того, кому задан вопрос – разработчику, производителю или конечному покупателю. В первом случае, ответ будет в большинстве своем восторженно-утвердительный., ведь именно разработчиков железа порадует унификация сигнальных уровней и топологии большинства шин системы! Производители системных плат, видеокарт и прочей обвязки ПК, скорее всего, с досадой припомнят Конфуция с его замечанием о жизни в эпоху перемен, ведь им теперь приходится наперед просчитывать баланс спроса на системы с новой, старой и смешанной архитектурой, а это влечет за собой неуверенность в правильности выбранной стратегии в плане маркетинга и логистики. С другой стороны, "мутная водичка" – подходящий момент для того, чтобы изменить расстановку сил и выбиться в лидеры.
Наверно, в самой странной ситуации останутся потребители, следившие за последними разработками и прикупившие себе самые продвинутые версии видеокарт с шиной AGP 8x. Вот уж кого уверяли, что круче некуда и это надолго! Да, возможности этого интерфейса действительно, до конца так и не были использованы, но время не ждет, на горизонте – новая 16x вершина, которую, вроде бы, обещают надолго. Слабым, но утешением могут служить два тезиса: во-первых, PCI Express – это действительно надолго; во-вторых, на протяжении 2004 года никто от старых добрых слотов отказываться не спешит, в большинстве своем новые платы будут обладать всем набором шин, включая PCI, AGP и PCI Express. Время для того, чтобы состариться, у ваших AGP 8x еще есть.



